

Nos posts anteriores, exploramos diversas áreas da Inteligência Artificial, desde visão computacional até chatbots inteligentes. Agora, chegou a hora de encarar o coração pulsante do Deep Learning, a tecnologia que impulsiona as IAs mais incríveis da atualidade: as Redes Neurais! 🧠✨ Vamos construir uma rede neural para previsão de diabetes em Python.
Se o termo “Redes Neurais” te soa complexo ou distante, relaxa! 😉 Neste post, vamos desmistificar esse conceito e mostrar que, com Python e a biblioteca Keras, construir e entender Redes Neurais pode ser mais acessível e empolgante do que você imagina! Prepare-se para desvendar o “cérebro” da IA e dar um salto rumo ao futuro do Deep Learning! 🚀
Redes neurais: Imitando o cérebro humano (de um jeito simplificado, claro!) 🤯
Primeiramente, o que são essas tais Redes Neurais e por que são chamadas de “cérebro” da IA? A inspiração vem do nosso próprio cérebro! Redes Neurais Artificiais (RNAs) são modelos computacionais que buscam simular o funcionamento das redes de neurônios biológicos presentes no cérebro humano (e de outros animais).
Claro, as RNAs são versões muito simplificadas do cérebro biológico, mas a ideia central é a mesma:
- Neurônios (Artificiais): Assim como o cérebro é composto por bilhões de neurônios interconectados, as RNAs são construídas com unidades básicas chamadas neurônios artificiais (ou nodos). Cada neurônio artificial recebe entradas, processa essas entradas e gera uma saída.
- Conexões (Sinapses): Os neurônios no cérebro se comunicam através de conexões chamadas sinapses. Nas RNAs, os neurônios artificiais também são conectados entre si por conexões ponderadas, onde cada conexão tem um “peso” que influencia a força da comunicação entre os neurônios.
- Aprendizado: O cérebro aprende ajustando a força das conexões entre os neurônios. As RNAs aprendem de forma similar, ajustando os pesos das conexões durante o processo de treinamento, com base nos dados de entrada e nos resultados desejados.
Em essência, uma Rede Neural é uma estrutura computacional complexa, composta por camadas de neurônios artificiais interconectados. Essas camadas processam a informação em etapas, extraindo características cada vez mais abstratas dos dados de entrada, até chegar a uma saída desejada (como uma classificação, uma previsão, etc.).
As redes neurais se tornaram a base do Deep Learning (aprendizado profundo)
- Aprendem representações complexas: As RNAs com muitas camadas (redes neurais “profundas”) são capazes de aprender representações hierárquicas e complexas dos dados, o que as torna muito poderosas para resolver problemas desafiadores em áreas como visão computacional, processamento de linguagem natural, reconhecimento de voz, jogos e muitas outras.
- Aprendizado automático de características: Diferente de algoritmos de Machine Learning mais tradicionais, as RNAs podem aprender as características relevantes dos dados automaticamente, sem precisar que um especialista as defina manualmente. É como se a própria rede neural “descobrisse” o que é importante nos dados para resolver a tarefa.
- Escalabilidade com dados e computação: As RNAs se beneficiam enormemente de grandes volumes de dados de treinamento e do poder de computação moderna (GPUs, etc.). Quanto mais dados e poder computacional, mais complexas e poderosas as redes neurais podem se tornar.
Python e Keras: Construindo redes neurais de forma descomplicada 🚀
Agora, como podemos construir e treinar Redes Neurais na prática? A resposta é Python e Keras!
- Python: Já sabemos que Python é a linguagem queridinha da IA, certo? Sintaxe clara, bibliotecas poderosas, comunidade enorme… Tudo isso se aplica ao Deep Learning também!
- Keras: É uma biblioteca de alto nível para construir e treinar Redes Neurais em Python. Keras é projetado para ser amigável, intuitivo e produtivo. Ela se integra perfeitamente com bibliotecas de backend de Deep Learning mais robustas, como TensorFlow (criado pelo Google) e PyTorch (criado pelo Facebook). Neste post, vamos usar Keras com backend TensorFlow.
Com Keras, você pode definir arquiteturas de Redes Neurais complexas com poucas linhas de código! Keras cuida da parte “chata” e complexa por baixo dos panos, permitindo que você se concentre nos conceitos e na lógica da sua rede neural. É como ter um “construtor de cérebros de IA” na ponta dos dedos! 🧙♂️
Mão na massa: Sua primeira rede neural com Python e Keras! 💻
Chegou a hora de programar! Vamos construir nossa primeira Rede Neural simples com Keras para resolver um problema de classificação binária (duas classes). Vamos usar um dataset de exemplo bem conhecido e didático: o dataset “Pima Indians Diabetes“. Este dataset contém informações médicas de pacientes indígenas Pima e o objetivo é prever se cada paciente tem ou não diabetes com base nessas informações.
Importar as bibliotecas essenciais
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow import keras
from tensorflow.keras import layers- pandas (pd): Para manipulação e análise de dados em formato de DataFrame.
- sklearn.model_selection.train_test_split: Para dividir dados em treino e teste.
- sklearn.preprocessing.StandardScaler: Para padronizar os dados (normalização).
- tensorflow (tf): Importa a biblioteca TensorFlow (backend do Keras).
- tensorflow.keras (keras): Importa a interface Keras da biblioteca TensorFlow.
- tensorflow.keras.layers (layers): Importa o módulo de layers do Keras, que usaremos para construir as camadas da nossa rede neural.
Carregar e preparar os dados
Baixe o dataset deste link, e copie o arquivo csv para a mesma pasta do código python. Agora, vamos carregar o dataset “Pima Indians Diabetes” usando pandas e prepará-lo para o treinamento da rede neural.
# Carregar o dataset Pima Indians Diabetes
data = pd.read_csv('diabetes.csv') # Certifique-se de ter o arquivo 'diabetes.csv' no mesmo diretório
# Separar características (features) e variável alvo (target)
X = data.drop('Outcome', axis=1) # Features (todas as colunas exceto 'Outcome')
y = data['Outcome'] # Variável alvo (coluna 'Outcome')
# Dividir dados em treino e teste
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y) # 20% para teste, estratificação para manter proporção das classes
# Padronizar os dados (normalização)
scaler = StandardScaler()
X_treino_scaled = scaler.fit_transform(X_treino) # Ajustar scaler nos dados de treino e transformar
X_teste_scaled = scaler.transform(X_teste) # Usar o mesmo scaler ajustado para transformar dados de teste- data = pd.read_csv(‘diabetes.csv’): Carrega o dataset do arquivo CSV ‘diabetes.csv’ usando pandas. Certifique-se de baixar o arquivo ‘diabetes.csv’ no mesmo diretório do seu script Python.
- X = data.drop(‘Outcome’, axis=1): Separa as características (features), que são todas as colunas do dataset exceto a coluna ‘Outcome’ (que é a variável alvo).
- y = data[‘Outcome’]: Separa a variável alvo (target), que é a coluna ‘Outcome’ (0 = não tem diabetes, 1 = tem diabetes).
- train_test_split(…): Divide os dados em conjuntos de treino (80%) e teste (20%). stratify=y garante que a proporção de classes (diabéticos e não diabéticos) seja mantida nos conjuntos de treino e teste.
- scaler = StandardScaler(): Cria um objeto StandardScaler para padronizar os dados. A padronização é importante para Redes Neurais, pois ajuda a acelerar o treinamento e melhorar o desempenho.
- X_treino_scaled = scaler.fit_transform(X_treino): Ajusta o scaler aos dados de treino (calcula a média e o desvio padrão de cada feature nos dados de treino) e transforma os dados de treino (subtrai a média e divide pelo desvio padrão).
- X_teste_scaled = scaler.transform(X_teste): Transforma os dados de teste usando o mesmo scaler ajustado nos dados de treino. É importante usar o mesmo scaler para garantir que os dados de treino e teste sejam padronizados da mesma forma.
Definir a arquitetura da rede neural com Keras
Agora, a parte emocionante! Vamos definir a arquitetura da nossa Rede Neural usando Keras Sequential API.
# Definir a arquitetura da rede neural (modelo Sequential)
modelo = keras.Sequential([
layers.Dense(12, activation='relu', input_shape=(X_treino_scaled.shape[1],)), # Camada de entrada e primeira camada oculta (12 neurônios, ReLU)
layers.Dense(8, activation='relu'), # Segunda camada oculta (8 neurônios, ReLU)
layers.Dense(1, activation='sigmoid') # Camada de saída (1 neurônio, Sigmoid para classificação binária)
])- modelo = keras.Sequential([…]): Cria um modelo Keras Sequential. Um modelo Sequential é uma pilha linear de camadas, adequado para arquiteturas de redes neurais mais simples.
- layers.Dense(12, activation=’relu’, input_shape=(X_treino_scaled.shape[1],)): Primeira camada (camada de entrada e primeira camada oculta).
- layers.Dense(12, …): Cria uma camada Densa (ou Fully Connected), que é o tipo de camada mais comum em Redes Neurais. 12 indica o número de neurônios nesta camada.
- activation=’relu’: Define a função de ativação para esta camada como ReLU (Rectified Linear Unit). ReLU é uma função de ativação não linear muito popular em redes neurais profundas, pois ajuda a acelerar o treinamento e evita o problema do desaparecimento do gradiente.
- input_shape=(X_treino_scaled.shape[1],): Define o formato da entrada para a primeira camada. X_treino_scaled.shape[1] obtém o número de features (colunas) nos dados de treino padronizados. Apenas a primeira camada precisa do input_shape, pois as camadas seguintes inferem o formato da entrada da camada anterior.
- layers.Dense(8, activation=’relu’): Segunda camada oculta. Similar à primeira camada, mas com 8 neurônios e também usando a função de ativação ReLU.
- layers.Dense(1, activation=’sigmoid’): Camada de saída.
- layers.Dense(1, …): Camada densa com apenas 1 neurônio.
- activation=’sigmoid’: Define a função de ativação para a camada de saída como Sigmoid. A função Sigmoid é usada em problemas de classificação binária porque ela escala a saída para um valor entre 0 e 1, que pode ser interpretado como a probabilidade de pertencer à classe positiva (neste caso, ter diabetes).
Compilar o modelo Keras
Antes de treinar o modelo, precisamos compilá-lo, configurando o otimizador, a função de perda e as métricas de avaliação.
# Compilar o modelo
modelo.compile(optimizer='adam', # Otimizador Adam (um dos mais populares)
loss='binary_crossentropy', # Função de perda Binary Crossentropy (para classificação binária)
metrics=['accuracy']) # Métrica de avaliação: acurácia- modelo.compile(…): Compila o modelo Keras, preparando-o para o treinamento.
- optimizer=’adam’: Define o otimizador como Adam. Otimizadores são algoritmos que ajustam os pesos da rede neural durante o treinamento para minimizar a função de perda. Adam é um otimizador muito popular e eficiente para redes neurais profundas.
- loss=’binary_crossentropy’: Define a função de perda como Binary Crossentropy. A função de perda mede o quão “erradas” estão as previsões do modelo em relação aos rótulos verdadeiros. Binary Crossentropy é a função de perda padrão para problemas de classificação binária.
- metrics=[‘accuracy’]: Define a métrica de avaliação como acurácia. A acurácia é a proporção de previsões corretas. Usaremos a acurácia para monitorar o desempenho do modelo durante o treinamento e avaliação.
Treinar o modelo
Agora, vamos treinar nossa Rede Neural com os dados de treino padronizados!
# Treinar o modelo
historico = modelo.fit(X_treino_scaled, y_treino, epochs=100, batch_size=10, validation_split=0.1, verbose=0) # Treinar por 100 épocas, batch size 10, 10% para validação- modelo.fit(…): Treina o modelo! O método fit() realiza o treinamento da rede neural.
- X_treino_scaled, y_treino: Dados de treino (features padronizadas e rótulos).
- epochs=100: Define o número de épocas de treinamento como 100. Uma época é uma iteração completa sobre todo o dataset de treino. Treinar por mais épocas pode melhorar o desempenho do modelo, mas também pode levar a overfitting (o modelo se ajusta muito bem aos dados de treino, mas generaliza mal para dados novos).
- batch_size=10: Define o batch size como 10. Durante o treinamento, os dados de treino são divididos em batches (lotes) de tamanho batch_size. O modelo calcula os gradientes e atualiza os pesos a cada batch. Batch size menor pode tornar o treinamento mais lento, mas pode ajudar a escapar de mínimos locais.
- validation_split=0.1: Define 10% dos dados de treino para validação. Durante o treinamento, o Keras usará esses 10% dos dados para validar o desempenho do modelo a cada época (sem usá-los para treinar). Isso ajuda a monitorar o overfitting e a ajustar o treinamento.
- verbose=0: Define o modo “verbose” como 0 para não exibir as barras de progresso e logs de treinamento (para deixar o output mais limpo no post). Se você quiser ver o progresso do treinamento, pode mudar para verbose=1 ou verbose=2.
- historico = …: O método fit() retorna um objeto History que contém informações sobre o treinamento, como a função de perda e a acurácia em cada época. Podemos usar esse objeto para plotar gráficos de treinamento (não faremos neste post para manter a simplicidade, mas é uma prática comum).
Avaliar o modelo
Após o treinamento, vamos avaliar o desempenho do modelo nos dados de teste padronizados.
# Avaliar o modelo nos dados de teste
loss, accuracy = modelo.evaluate(X_teste_scaled, y_teste, verbose=0) # Avaliar nos dados de teste
print(f"Perda (Loss) nos dados de teste: {loss:.4f}")
print(f"Acurácia nos dados de teste: {accuracy:.4f}")- modelo.evaluate(…): Avalia o modelo nos dados de teste. Retorna a função de perda e as métricas especificadas durante a compilação (neste caso, loss e accuracy).
- X_teste_scaled, y_teste: Dados de teste padronizados e rótulos.
- verbose=0: Não exibir logs durante a avaliação.
- print(f”Perda (Loss) nos dados de teste: {loss:.4f}”): Imprime a função de perda nos dados de teste.
- print(f”Acurácia nos dados de teste: {accuracy:.4f}”): Imprime a acurácia nos dados de teste.
Realizar Previsões com o modelo treinado
Vamos criar uma função chamada prever_diabetes que encapsula todo o processo de previsão para um novo paciente.
def prever_diabetes(dados_paciente, modelo_treinado, scaler_treinado):
"""
Faz a previsão de diabetes para um paciente usando o modelo de rede neural treinado.
Args:
dados_paciente (list): Lista com os valores das características do paciente (na mesma ordem das colunas do dataset).
modelo_treinado (keras.Sequential): Modelo de rede neural treinado.
scaler_treinado (StandardScaler): Scaler ajustado nos dados de treino.
Returns:
str: Resultado da previsão ("Diabetes" ou "Não Diabetes").
"""
# Converter dados do paciente para array NumPy e reshape
dados_paciente_np = np.array(dados_paciente).reshape(1, -1) # Reshape para 1 amostra, N features
# Padronizar os dados do paciente usando o scaler treinado
dados_paciente_scaled = scaler_treinado.transform(dados_paciente_np)
# Fazer a previsão usando o modelo treinado
probabilidade_diabetes = modelo_treinado.predict(dados_paciente_scaled)[0][0] # Obter probabilidade (valor escalar)
# Definir um limiar (threshold) para classificar (ex: 0.5)
limiar = 0.5
# Classificar com base no limiar
if probabilidade_diabetes >= limiar:
resultado_previsao = "Diabetes"
else:
resultado_previsao = "Não Diabetes"
return resultado_previsao, probabilidade_diabetes # Retornar resultado e probabilidade- def prever_diabetes(dados_paciente, modelo_treinado, scaler_treinado):: Define a função prever_diabetes que recebe os dados do paciente, o modelo treinado e o scaler treinado como argumentos.
- dados_paciente_np = np.array(dados_paciente).reshape(1, -1): Converte a lista de dados do paciente para um array NumPy e faz um reshape para garantir que tenha o formato correto (1 amostra, N features), que é o formato esperado pelo scikit-learn e Keras para previsões individuais.
- dados_paciente_scaled = scaler_treinado.transform(dados_paciente_np): Padroniza os dados do paciente usando o scaler_treinado que foi ajustado nos dados de treino na Parte 1. Usamos .transform() e não .fit_transform(), pois queremos usar a mesma padronização aprendida nos dados de treino.
- probabilidade_diabetes = modelo_treinado.predict(dados_paciente_scaled)[0][0]: Faz a previsão! Usa modelo_treinado.predict() para obter a probabilidade de diabetes para os dados do paciente padronizados. [0][0] extrai o valor escalar da probabilidade do array NumPy retornado por predict().
- limiar = 0.5: Define um limiar (threshold) de 0.5 para classificar a previsão. Se a probabilidade for maior ou igual a 0.5, consideramos “Diabetes”, caso contrário, “Não Diabetes”. Você pode ajustar este limiar se quiser tornar o modelo mais ou menos sensível à detecção de diabetes.
- return resultado_previsao, probabilidade_diabetes: Retorna o resultado da previsão (“Diabetes” ou “Não Diabetes”) e a probabilidade de diabetes.
Criando a interface de usuário no terminal
Agora, vamos criar um loop simples para interagir com o usuário no terminal, pedir os dados do paciente e exibir a previsão.
# Interface de usuário no terminal
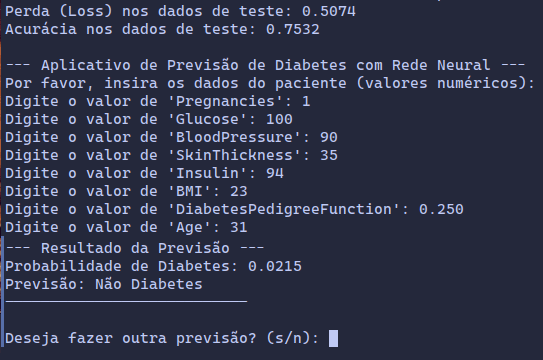
print("\n--- Aplicativo de Previsão de Diabetes com Rede Neural ---")
print("Por favor, insira os dados do paciente (valores numéricos):")
# Nomes das colunas de características (features) - importante para pedir os dados na ordem correta
nomes_features = X_treino.columns.tolist() # Obter nomes das colunas do DataFrame X_treino
while True: # Loop para permitir múltiplas previsões
dados_paciente_input = [] # Lista para armazenar os dados do paciente inseridos pelo usuário
for nome_feature in nomes_features: # Iterar sobre os nomes das features para pedir os dados na ordem correta
while True: # Loop para garantir que o usuário insira um valor numérico válido para cada feature
valor_str = input(f"Digite o valor de '{nome_feature}': ")
try:
valor = float(valor_str) # Tentar converter a entrada para float
dados_paciente_input.append(valor) # Adicionar valor numérico à lista
break # Sair do loop interno se a conversão for bem-sucedida
except ValueError:
print("Valor inválido. Por favor, digite um número.") # Pedir para o usuário digitar um valor numérico válido
# Fazer a previsão usando a função prever_diabetes
resultado, probabilidade = prever_diabetes(dados_paciente_input, modelo, scaler) # Usar 'modelo' e 'scaler' treinados na Parte 1
# Exibir o resultado da previsão para o usuário
print("\n--- Resultado da Previsão ---")
print(f"Probabilidade de Diabetes: {probabilidade:.4f}")
print(f"Previsão: {resultado}")
print("---------------------------\n")
# Perguntar se o usuário quer fazer outra previsão
continuar = input("Deseja fazer outra previsão? (s/n): ")
if continuar.lower() != 's':
break # Sair do loop principal se o usuário não quiser continuar
print("Obrigado por usar o Aplicativo de Previsão de Diabetes! Até mais!")Código completo: Sua primeira rede neural com Python e Keras
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from tensorflow import keras
from tensorflow.keras import layers
# Carregar o dataset Pima Indians Diabetes
data = pd.read_csv('diabetes.csv')
X = data.drop('Outcome', axis=1)
y = data['Outcome']
# Dividir dados em treino e teste
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size=0.2, random_state=42, stratify=y)
# Padronizar os dados
scaler = StandardScaler()
X_treino_scaled = scaler.fit_transform(X_treino)
X_teste_scaled = scaler.transform(X_teste)
# Definir a arquitetura da rede neural (modelo Sequential)
modelo = keras.Sequential([
layers.Dense(12, activation='relu', input_shape=(X_treino_scaled.shape[1],)),
layers.Dense(8, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
# Compilar o modelo
modelo.compile(optimizer='adam',
loss='binary_crossentropy',
metrics=['accuracy'])
# Treinar o modelo
historico = modelo.fit(X_treino_scaled, y_treino, epochs=100, batch_size=10, validation_split=0.1, verbose=0)
# Avaliar o modelo nos dados de teste
loss, accuracy = modelo.evaluate(X_teste_scaled, y_teste, verbose=0)
print(f"Perda (Loss) nos dados de teste: {loss:.4f}")
print(f"Acurácia nos dados de teste: {accuracy:.4f}")
def prever_diabetes(dados_paciente, modelo_treinado, scaler_treinado):
"""
Faz a previsão de diabetes para um paciente usando o modelo de rede neural treinado.
Args:
dados_paciente (list): Lista com os valores das características do paciente (na mesma ordem das colunas do dataset).
modelo_treinado (keras.Sequential): Modelo de rede neural treinado.
scaler_treinado (StandardScaler): Scaler ajustado nos dados de treino.
Returns:
str: Resultado da previsão ("Diabetes" ou "Não Diabetes").
"""
# Converter dados do paciente para array NumPy e reshape
dados_paciente_np = np.array(dados_paciente).reshape(1, -1) # Reshape para 1 amostra, N features
# Padronizar os dados do paciente usando o scaler treinado
dados_paciente_scaled = scaler_treinado.transform(dados_paciente_np)
# Fazer a previsão usando o modelo treinado
probabilidade_diabetes = modelo_treinado.predict(dados_paciente_scaled)[0][0] # Obter probabilidade (valor escalar)
# Definir um limiar (threshold) para classificar (ex: 0.5)
limiar = 0.5
# Classificar com base no limiar
if probabilidade_diabetes >= limiar:
resultado_previsao = "Diabetes"
else:
resultado_previsao = "Não Diabetes"
return resultado_previsao, probabilidade_diabetes # Retornar resultado e probabilidade
# Interface de usuário no terminal
print("\n--- Aplicativo de Previsão de Diabetes com Rede Neural ---")
print("Por favor, insira os dados do paciente (valores numéricos):")
# Nomes das colunas de características (features) - importante para pedir os dados na ordem correta
nomes_features = X_treino.columns.tolist() # Obter nomes das colunas do DataFrame X_treino
while True: # Loop para permitir múltiplas previsões
dados_paciente_input = [] # Lista para armazenar os dados do paciente inseridos pelo usuário
for nome_feature in nomes_features: # Iterar sobre os nomes das features para pedir os dados na ordem correta
while True: # Loop para garantir que o usuário insira um valor numérico válido para cada feature
valor_str = input(f"Digite o valor de '{nome_feature}': ")
try:
valor = float(valor_str) # Tentar converter a entrada para float
dados_paciente_input.append(valor) # Adicionar valor numérico à lista
break # Sair do loop interno se a conversão for bem-sucedida
except ValueError:
print("Valor inválido. Por favor, digite um número.") # Pedir para o usuário digitar um valor numérico válido
# Fazer a previsão usando a função prever_diabetes
resultado, probabilidade = prever_diabetes(dados_paciente_input, modelo, scaler) # Usar 'modelo' e 'scaler' treinados na Parte 1
# Exibir o resultado da previsão para o usuário
print("\n--- Resultado da Previsão ---")
print(f"Probabilidade de Diabetes: {probabilidade:.4f}")
print(f"Previsão: {resultado}")
print("---------------------------\n")
# Perguntar se o usuário quer fazer outra previsão
continuar = input("Deseja fazer outra previsão? (s/n): ")
if continuar.lower() != 's':
break # Sair do loop principal se o usuário não quiser continuar
print("Obrigado por usar o Aplicativo de Previsão de Diabetes! Até mais!")Execute o código completo! Ele irá primeiro treinar o modelo (se você não tiver o modelo e scaler já treinados), e depois irá iniciar o “Aplicativo de Previsão de Diabetes” no terminal. Você poderá inserir os dados de um paciente um por um, e o aplicativo irá usar a sua Rede Neural treinada para prever se o paciente tem ou não diabetes! 🎉
Parabéns! Você Criou um Aplicativo Prático de IA com Redes Neurais! 🏆🎉
Em resumo, você aprendeu a dar utilidade prática para a Rede Neural que construímos! Você viu como carregar o modelo treinado, preparar dados de entrada para previsão, fazer previsões e criar uma interface simples para o usuário interagir com a IA. Isso demonstra o ciclo completo de desenvolvimento e aplicação de um modelo de Deep Learning!
⚠️ Lembre-se, este é um exemplo didático e simplificado, e não deve ser usado para diagnósticos médicos reais. Contudo, ele ilustra o potencial das Redes Neurais e da IA para resolver problemas práticos em diversas áreas, incluindo a saúde.
Próximos passos rumo a aplicações de IA do mundo real 🚀
- Melhorar a Precisão do Modelo: Para aplicações reais, é fundamental aumentar a precisão do modelo. Isso pode envolver:
- Coletar mais dados de treinamento: Quanto mais dados, melhor o modelo pode aprender e generalizar.
- Aprimorar a arquitetura da rede neural: Experimentar arquiteturas mais complexas, com mais camadas, diferentes tipos de camadas, técnicas de regularização, etc.
- Otimizar os hiperparâmetros do modelo: Ajustar parâmetros como learning rate, batch size, número de épocas, etc.
- Usar técnicas de aumento de dados: Criar variações dos dados de treino para aumentar a diversidade e robustez do modelo.
- Criar Interfaces de Usuário Mais Elaboradas: Para aplicações reais, interfaces de terminal podem não ser suficientes. Explore a criação de interfaces gráficas (GUIs) ou interfaces web para tornar o aplicativo mais amigável e acessível para os usuários.
- Integrar com Sistemas e Dados Reais: Pense em como integrar seu modelo de IA com sistemas de dados reais, como prontuários eletrônicos, bancos de dados médicos, APIs de serviços de saúde, etc., para criar aplicações de IA que realmente impactem o mundo real.
- Considerar Aspectos Éticos e de Responsabilidade: Em aplicações na área da saúde e outras áreas sensíveis, é crucial considerar os aspectos éticos e de responsabilidade do uso da IA. Garantir a privacidade dos dados, evitar vieses nos modelos, explicar as limitações da IA e sempre manter a supervisão humana são aspectos fundamentais.
E aí, o que achou de ver sua Rede Neural prever diabetes na prática? Experimente rodar o código, insira diferentes dados de pacientes e veja os resultados. E não se esqueça de compartilhar suas dúvidas, ideias e como você imagina usar Redes Neurais em aplicações reais! Adoramos aprender e construir o futuro da IA juntos! 😊
Até a próxima, e continue aplicando a Inteligência Artificial de Redes Neurais no mundo real com Python e Keras! 🚀✨🩺💻🧠
1 comentário em “Redes neurais para iniciantes: Desvendando o “cérebro” da IA com Python e Keras”