

A maioria das conversas sobre Machine Learning e Inteligência Artificial gira em torno de Python, notebooks Jupyter e frameworks como PyTorch e TensorFlow. E com razão: são ferramentas poderosas para pesquisa e treinamento de modelos.
Mas e quando o modelo está pronto? Quando a ciência de dados termina e a hora de levar a inteligência para a vida real chega? É aí que o mundo dos MLOps (Machine Learning Operations) entra em jogo. E é nesse palco que o Java não apenas compete, mas começa a brilhar de uma forma que muitos jamais imaginaram.
Este artigo é para desmistificar a ideia de que o Java é uma linguagem “legada” para IA. Vamos mergulhar em uma das maiores inovações da plataforma nos últimos anos — as Virtual Threads — e provar, com um experimento prático e código completo, como elas estão revolucionando a construção de microsserviços de IA, tornando-os mais escaláveis e eficientes do que nunca.
O problema: O gargalo das threads tradicionais
Para um modelo de ML funcionar em produção, ele precisa ser “servido”. Isso geralmente significa encapsulá-lo em uma API REST que recebe dados, executa a inferência e retorna uma resposta.
O grande segredo (e o maior gargalo) é que a maioria das operações em um microsserviço não são CPU-bound (limitadas pelo processamento), mas sim I/O-bound (limitadas por operações de entrada/saída). Pense em buscar dados de um banco de dados, chamar outra API para enriquecer os dados ou até mesmo enviar o resultado para um sistema de mensageria.
As threads tradicionais do Java são diretamente mapeadas para threads do sistema operacional. Elas são “pesadas” e caras. Quando uma thread tradicional fica bloqueada esperando uma resposta de um banco de dados, ela simplesmente fica parada, ocupando um recurso valioso. Se você tiver mil requisições simultâneas, seu pool de threads pode esgotar rapidamente, transformando seu serviço em um semáforo paralisado e causando picos de latência e quedas no throughput.
A solução: A leveza e a magia das Virtual Threads
O Projeto Loom, introduzido no Java 21, muda completamente essa dinâmica com as Virtual Threads.
Pense em um garçom em um restaurante lotado.
- Garçom tradicional (thread do sistema): Pega o seu pedido e fica parado na cozinha esperando o prato sair. Ele não pode atender mais ninguém enquanto espera.
- Garçom virtual (virtual thread): Pega seu pedido, entrega na cozinha e imediatamente vai atender outras mesas. Quando o prato fica pronto, ele é notificado e volta para servir a sua mesa.
As Virtual Threads são extremamente leves e gerenciadas pela JVM, não pelo sistema operacional. Quando uma delas encontra uma operação de I/O que a bloquearia, a JVM a “desmonta” temporariamente, liberando a thread do sistema para que ela possa executar outra Virtual Thread. O resultado? Você pode ter milhões de Virtual Threads ativas sem esgotar os recursos do sistema, garantindo um throughput massivo e uma escalabilidade sem precedentes.
O experimento prático: MLOps na prática
Vamos construir um simples microsserviço Spring Boot para demonstrar essa diferença na prática. Nosso serviço terá duas endpoints:
/legacy: Utiliza threads tradicionais./virtual: Utiliza Virtual Threads.
Ambas as endpoints farão o mesmo: simular uma operação de I/O (buscar dados) e uma operação de CPU (inferência do modelo).
1. Dependências do projeto (pom.xml)
Comece criando um projeto Spring Boot e adicione as seguintes dependências.
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.5</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>br.com.flipbits.mlops</groupId>
<artifactId>MLOps</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>MLOps</name>
<description>MLOps Java</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>21</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>2. O serviço de inferência (ModelService.java)
Vamos criar um serviço simples para simular as duas etapas do nosso pipeline de MLOps.
package br.com.flipbits.mlops.MLOps;
import org.springframework.stereotype.Service;
@Service
public class ModelService {
/**
* Simula uma operação de I/O-bound, como buscar dados de um banco de dados ou API externa.
* Esta é a parte "lenta" que causa bloqueio.
*/
public void fetchDataFromExternalSource() {
try {
Thread.sleep(100); // Simula 100ms de latência de I/O
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
}
/**
* Simula uma operação de CPU-bound, como a inferência de um modelo de ML.
* Esta é a parte que requer poder de processamento.
*/
public String runModelInference(String data) {
// Simula um cálculo complexo. Para fins de demonstração, apenas uma transformação de string.
String result = "Inference for '" + data + "' completed at " + System.currentTimeMillis();
// Em um cenário real, aqui entraria a chamada ao modelo (ex: via DL4J, ONNX runtime, etc.)
return result;
}
}3. O controlador com threads antigas e novas (MLOpsController.java)
Agora, a parte principal. Vamos criar um controlador com duas endpoints.
package br.com.flipbits.mlops.MLOps;
import java.util.concurrent.CompletableFuture;
import java.util.concurrent.CompletionStage;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class MLOpsController {
private final ModelService modelService;
// Executor com pool de threads tradicionais (limite de 200 threads).
// Esse é o modelo "legado" que pode esgotar rapidamente.
private final ExecutorService legacyExecutor = Executors.newFixedThreadPool(200);
// Executor com Virtual Threads, que podem escalar a milhões de threads.
private final ExecutorService virtualExecutor = Executors.newVirtualThreadPerTaskExecutor();
public MLOpsController(ModelService modelService) {
this.modelService = modelService;
}
@GetMapping("/legacy")
public String legacyInference() throws Exception {
// Envio a tarefa para o executor de threads tradicionais.
Future<String> future = legacyExecutor.submit(() -> {
modelService.fetchDataFromExternalSource();
return modelService.runModelInference("Legacy Request");
});
return future.get(); // Bloqueia a thread da web para obter o resultado.
}
@GetMapping("/virtual")
public CompletionStage<String> virtualInference() {
// A magia das Virtual Threads. A tarefa é executada em uma Virtual Thread.
// O servidor web (Spring) não precisa de um pool de threads de 200+.
// A thread da web não é bloqueada.
return CompletableFuture.supplyAsync(() -> {
modelService.fetchDataFromExternalSource();
return modelService.runModelInference("Virtual Thread Request");
}, virtualExecutor);
}
}4. Executando o experimento e analisando os resultados
Execute o aplicativo: No terminal, vá para a pasta raiz do projeto e execute:
./mvnw spring-boot:runTeste as endpoints: Use uma ferramenta de teste de carga como JMeter ou k6.
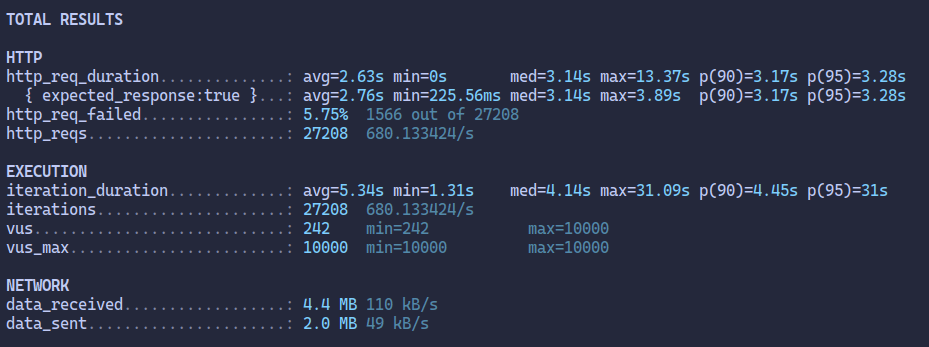
A verdadeira diferença será vista sob carga. Ao usar uma ferramenta de teste de carga para simular 10000 usuários simultâneas por 10 segundos, você verá que o endpoint /legacy (imagem 1) começará a ter problemas de latência e possivelmente timeouts, pois seu pool de 200 threads se esgotará rapidamente.
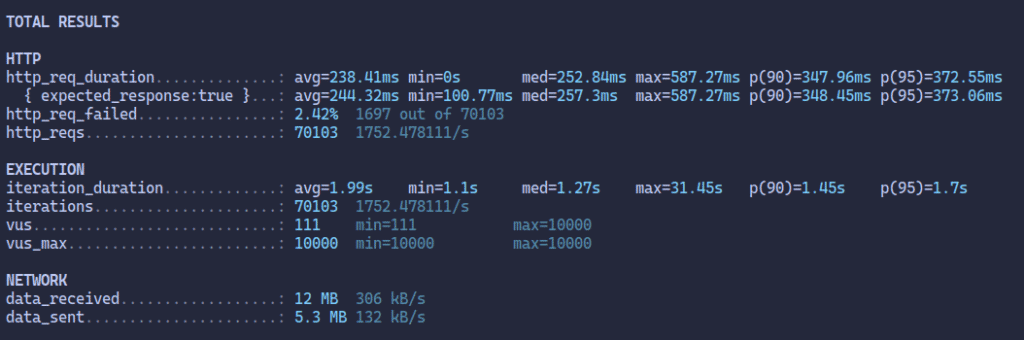
O endpoint /virtual (imagem 2), por outro lado, continuará respondendo de forma consistente, com uma latência muito mais baixa e um throughput significativamente maior.
Conclusão: O Java está pronto para a produção de IA
O que este experimento nos mostra é claro: o Java não está parado no tempo. As Virtual Threads não são uma ferramenta para o treinamento de modelos (que continua sendo um reino onde Python e hardware especializado dominam), mas sim para a produção e escalabilidade em larga escala.
Ao combinar a robustez, o ecossistema maduro e a performance da JVM com a concorrência eficiente das Virtual Threads, o Java se posiciona como a escolha ideal para construir a espinha dorsal de sua infraestrutura de MLOps.
Está na hora de parar de pensar em Java como apenas uma linguagem para sistemas legados e enxergá-lo como um agente de mudança na era da Inteligência Artificial em produção. E você, está pronto para dar o salto?