

Com o boom dos modelos de linguagem nos últimos anos, a paisagem de IA se transformou radicalmente. Hoje temos acesso não apenas a um modelo dominante, mas a uma constelação de LLMs (Large Language Models) com diferentes propósitos, licenças, eficiências e arquiteturas.
Mas com tantos nomes surgindo — GPT-4, LLaMA, Mistral, Gemini, Claude, e por aí vai — surge a dúvida: qual é o melhor?
A resposta curta é: depende. A resposta longa é o que vamos explorar aqui.
Comparar LLMs é como comparar carros de alto desempenho: todos parecem velozes, mas alguns são projetados para estabilidade, outros para aceleração, alguns para autonomia e outros para luxo. O “motor” pode ser semelhante (Transformer decoder-only), mas os detalhes são onde mora a diferença.
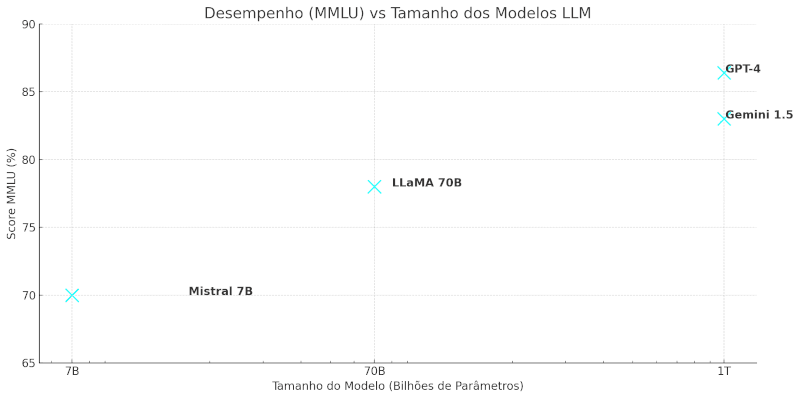
Nota sobre terminologia: Ao longo do artigo, você verá modelos sendo descritos como tendo “7B”, “70B” ou “1T” de parâmetros. Esses sufixos significam:
- B = bilhões de parâmetros (do inglês billion).
- T = trilhões de parâmetros. Esses números representam a quantidade total de pesos treináveis no modelo e são um indicativo (mas não uma garantia!) da sua capacidade de memorizar e generalizar.
Panorama geral: Quem é quem nessa corrida?
Vamos começar com um resumo das quatro arquiteturas mais faladas no momento:
| Modelo | Parâmetros | Arquitetura | Licença | Foco |
|---|---|---|---|---|
| GPT-4 | ~1T* | Mixture of Experts | Proprietária | Versatilidade comercial |
| Gemini 1.5 | ??? | Multimodal Transformer | Proprietária | Multimodalidade ampla |
| LLaMA 3 | 8B / 70B | Transformer decoder-only | Open-ish (Meta) | Pesquisa e fine-tuning |
| Mistral 7B | 7B | Transformer otimizado | Apache 2.0 | Performance local |

* O número de parâmetros do GPT-4 não foi oficialmente revelado, mas estimativas giram em torno de 1 trilhão, com arquiteturas de tipo MoE (Mixture of Experts).
Sob o Capô: Arquitetura e Design
GPT-4: Gigante, mas eficiente
GPT-4 introduziu uma arquitetura Mixture of Experts (MoE), onde apenas uma fração dos neurônios é ativada a cada forward pass. Isso reduz o custo computacional sem sacrificar capacidade. Pense nele como um time de especialistas onde apenas os mais relevantes para a tarefa atual entram em ação.
- Vantagens: Grande capacidade sem custo proporcional.
- Desvantagens: Black box total. Sem acesso a pesos, arquitetura ou dados.
Gemini: O modelo multimodal da Google DeepMind
O Gemini é um modelo projetado desde o início com multimodalidade nativa — ou seja, ele entende e gera texto, imagem, áudio e possivelmente vídeo em uma mesma arquitetura unificada.
- Arquitetura: Transformer multimodal unificado.
- Destaques: Fortemente integrado ao ecossistema da Google (como Bard, Workspace, etc).
- Limitadores: Totalmente proprietário, com pouca transparência técnica.
A proposta é ser o modelo universal, cobrindo desde interações em linguagem natural até raciocínio visual e manipulação de código.
LLaMA 3: Modular e robusto
LLaMA, da Meta, é um modelo puro de Transformer decoder-only, sem Mixture of Experts. A arquitetura segue os padrões “clássicos”, mas com melhorias como:
- SwiGLU como função de ativação. Trata-se de uma combinação entre duas operações lineares com a função GLU (Gated Linear Unit), que melhora o fluxo de gradientes e permite representações mais expressivas. É mais estável e eficiente que funções como ReLU ou GELU em modelos grandes.
- Normalização (LayerNorm) no final.
- Treinamento com tokenization de altíssima eficiência (SentencePiece).
A grande força do LLaMA é sua abertura parcial: você pode baixar os pesos (em ambientes autorizados), fazer fine-tuning e rodar localmente.
Mistral: Compacto e inteligente
O modelo Mistral se destaca pelo uso de técnicas arquiteturais otimizadas:
- Sliding Window Attention: Permite contextos longos com menos custo.
- Grouped Query Attention (GQA): Reduz complexidade computacional mantendo performance.
- Tokenization eficiente: Baseado em BPE otimizado.
Com apenas 7B de parâmetros, o Mistral rivaliza com modelos bem maiores em tarefas práticas, especialmente se ajustado com LoRA ou QLoRA.

Treinamento: Dados, Métodos e Filosofia
GPT-4
- Dados: Mistura privada de textos da internet, livros e outros (não divulgados).
- Métodos: Pretraining massivo + RLHF (aprendizado por reforço com feedback humano).
- Filosofia: “Quanto mais controle e dados, melhor o resultado comercial.”
Gemini
- Dados: Fontes diversas, incluindo dados visuais e auditivos, não divulgados publicamente.
- Métodos: Multimodal pretraining + instruções refinadas.
- Filosofia: “Um modelo para todas as tarefas cognitivas digitais.”
LLaMA
- Dados: Mistura de conjuntos públicos, como CommonCrawl, ArXiv, Wikipedia, StackExchange, entre outros.
- Métodos: Pretraining supervisionado + alinhamento opcional.
- Filosofia: “Open research. Facilitar o avanço da comunidade.”
Mistral
- Dados: Completamente baseados em fontes abertas.
- Métodos: Engenharia intensa de dataset + treinamento eficiente.
- Filosofia: “Maximizar performance com o mínimo de peso.”
Eficiência e Performance
| Modelo | Velocidade (tokens/s) | Context Window | Memória RAM (estimada) |
| GPT-4 | Variável (cloud) | 128k* | Datacenter-level |
| Gemini 1.5 | Variável (cloud) | 1M (streaming) | Datacenter-level |
| LLaMA 3 | ~25-50 em GPU local | 8k-32k | ~30-40 GB |
| Mistral 7B | ~60+ em GPU local | 8k | ~16 GB |
* GPT-4 Turbo possui context window de até 128k tokens, mas com custo e latência mais altos.
Mistral pode ser rodado em placas como RTX 3090 com boa performance. LLaMA exige GPUs mais robustas ou precisa ser quantizado (ex: GGUF, QLoRA) para rodar bem em CPUs. Gemini e GPT, por serem fechados, só operam via nuvem.
Casos de Uso Reais
GPT-4
- Assistentes conversacionais robustos.
- Automação de tarefas complexas (agentes autônomos).
- Ferramentas SaaS com IA natural.
Gemini
- Aplicações multimodais (texto, imagem, áudio).
- Integração com produtos Google (Docs, Sheets, etc).
- Agentes com raciocínio contextual em múltiplos formatos.
LLaMA
- Soluções locais para empresas com dados sensíveis.
- Pesquisa e experimentação com fine-tuning.
- Desenvolvimento de IA privativa (sem API externa).
Mistral
- Integração em apps leves e responsivos.
- Execução local em GPUs de consumidor.
- Projetos com foco em latência baixa e controle total.
Exemplos práticos:
- Um chatbot de suporte rodando localmente? Mistral com LoRA.
- Um gerador de relatórios offline? LLaMA com fine-tuning específico.
- Um produto SaaS com escalabilidade global? GPT-4 via API.
- Um assistente pessoal que analisa imagens e fala? Gemini multimodal.
O Futuro: Local vs Nuvem?
A grande questão não é apenas qual modelo é mais capaz, mas sim: você precisa mesmo da API mais cara e “inteligente”?
Modelos como LLaMA e Mistral mostram que é possível obter resultados surpreendentes com setups locais, inclusive em edge computing. Para muitas aplicações, especialmente onde privacidade e controle são cruciais, esses modelos são mais vantajosos.
Ao mesmo tempo, se você precisa de multimodalidade avançada ou integração direta com produtos como Google Workspace, o Gemini pode ser mais interessante que o GPT.
Conclusão: Quando usar cada um?
| Situação | Melhor escolha |
| Aplicativo comercial com integração web | GPT-4 via API |
| Projeto local com foco em controle total | LLaMA |
| App leve, responsivo e com hardware limitado | Mistral |
| Pesquisa ou prototipagem com fine-tuning | LLaMA / Mistral |
| Soluções altamente especializadas em edge | Mistral (quantizado) |
| Projeto multimodal com imagens e áudio | Gemini via API |
Se você quer explorar mais ou deseja um tutorial de como rodar Mistral ou LLaMA localmente com quantização e fine-tuning, deixe um comentário ou envie uma mensagem. Posso escrever o próximo post sobre isso.
Gostou desse tipo de análise? Compartilhe com outros devs e vamos fortalecer o conhecimento sobre IA que vai além da hype.
Você também pode gostar de: