

Já se perguntou como as empresas descobrem o que as pessoas estão achando de seus produtos ou serviços nas redes sociais? Ou como analistas políticos conseguem prever o resultado de uma eleição monitorando o humor dos eleitores no Twitter? A resposta está na análise de sentimentos em Java, uma poderosa ferramenta que combina o Processamento de Linguagem Natural (PLN) e a linguagem Java para extrair e classificar emoções expressas em textos.
A análise de sentimentos, também conhecida como mineração de opiniões, é uma área da Inteligência Artificial que se dedica a identificar e categorizar o tom emocional por trás de um texto. Em outras palavras, ela permite que um computador “entenda” se uma frase expressa uma opinião positiva, negativa ou neutra. E quando aplicamos essa técnica aos tweets, o resultado é fascinante: podemos monitorar em tempo real a opinião pública sobre qualquer assunto, desde o lançamento de um novo produto até a reação a um evento político importante.
Neste post, vamos embarcar em uma jornada prática e emocionante para construir nosso próprio analisador de sentimentos para tweets usando Java! Prepare-se para desvendar os segredos da PLN, dominar as bibliotecas Java essenciais e construir uma aplicação que coloca a inteligência artificial ao seu serviço. O objetivo é ambicioso, mas totalmente alcançável: criar um sistema capaz de analisar tweets e determinar se a mensagem expressa um sentimento positivo, negativo ou neutro, tudo isso com a elegância e o poder da linguagem Java. Vamos nessa!
O que é Processamento de Linguagem Natural (PLN)?
O Processamento de Linguagem Natural (PLN), ou Natural Language Processing (NLP), é um campo multidisciplinar da Inteligência Artificial que se dedica a criar sistemas capazes de entender, interpretar e gerar linguagem humana de forma inteligente. Imagine um mundo onde as máquinas pudessem conversar conosco, traduzir idiomas automaticamente, resumir textos complexos e até mesmo escrever poemas! Esse é o potencial do PLN.
Para alcançar esse objetivo, o PLN combina técnicas de ciência da computação, linguística, estatística e machine learning. Ele permite que os computadores processem e analisem grandes quantidades de texto, extraindo informações relevantes, identificando padrões e, crucialmente para o nosso projeto, compreendendo o sentimento expresso nas palavras.
As etapas básicas do PLN geralmente envolvem:
- Tokenização: Quebrar o texto em unidades menores, como palavras ou frases (os “tokens”).
- Remoção de Stop Words: Eliminar palavras comuns que não carregam muito significado (ex: “o”, “a”, “de”, “em”).
- Lematização/Stemming: Reduzir as palavras à sua forma base (ex: “correndo” -> “correr”). Isso ajuda a agrupar palavras com significados semelhantes.
- Análise Sintática: Identificar a estrutura gramatical das frases (ex: sujeito, verbo, objeto).
- Análise Semântica: Compreender o significado das palavras e frases no contexto.
- Modelagem de Tópicos: Identificar os principais temas abordados em um texto.
A escolha de Java para tarefas de PLN pode parecer inusitada para alguns, mas ela oferece diversas vantagens. Java é uma linguagem robusta, multiplataforma e com uma vasta comunidade, o que significa que temos acesso a uma grande variedade de bibliotecas e ferramentas de PLN maduras e bem documentadas.
Além disso, a performance do Java é excelente, o que é crucial para processar grandes volumes de texto de forma eficiente. Portanto, Java é uma excelente escolha para construir soluções inteligentes de PLN, desde analisadores de sentimentos até chatbots e sistemas de tradução automática.
Preparando os dados: Tweets como matéria-prima para a inteligência
Antes de mergulharmos no código e começarmos a analisar os sentimentos dos tweets, precisamos garantir que nossos dados estejam limpos, organizados e prontos para serem processados. Afinal, como diz o ditado, “lixo entra, lixo sai”! A qualidade dos nossos dados é fundamental para a precisão do nosso analisador de sentimentos.
Existem diversas formas de obter tweets para análise:
- API do Twitter: O Twitter oferece uma API (Interface de Programação de Aplicações) que permite coletar tweets em tempo real com base em diferentes critérios, como palavras-chave, hashtags, localização, etc. Essa é a forma mais direta e atualizada de obter dados, mas requer a criação de uma conta de desenvolvedor e o uso de chaves de autenticação.
- Datasets Prontos: Existem diversos datasets públicos de tweets disponíveis online, que já foram coletados e pré-processados por outras pessoas. Essa é uma opção mais rápida e fácil para começar, mas é importante verificar a qualidade e a relevância dos dados para o seu projeto. Alguns datasets populares incluem o “Sentiment140” e o “Airline Sentiment Dataset”.
Para este post, vamos utilizar o dataset de tweets “Airline Sentiment Dataset”, em formato de texto (ex: um arquivo CSV onde cada linha representa um tweet), que pode ser obtido deste link.
O próximo passo é pré-processar esses tweets para remover ruídos e deixá-los mais adequados para a análise. Algumas das etapas de pré-processamento mais comuns incluem:
- Remover URLs: Links e URLs não contribuem para a análise de sentimentos e podem ser removidos.
- Remover Menções (@usuário): Menções a outros usuários geralmente não são relevantes para o sentimento do tweet.
- Remover Hashtags (#palavra): Hashtags podem ser úteis para identificar tópicos, mas geralmente não influenciam o sentimento em si.
- Remover Pontuação e Caracteres Especiais: Pontuação e caracteres especiais podem atrapalhar a tokenização e a lematização.
- Converter para Minúsculas: Converter todo o texto para minúsculas garante que palavras como “Bom” e “bom” sejam tratadas da mesma forma.
- Remover Stop Words: Conforme mencionado anteriormente, stop words como “o”, “a”, “de”, “em” podem ser removidas para reduzir o ruído.
É importante lembrar que nem todas as etapas de pré-processamento são necessárias em todos os casos. A escolha das etapas a serem aplicadas depende das características do seu dataset e dos seus objetivos de análise. O importante é garantir que seus dados estejam o mais limpos e organizados possível antes de prosseguir para as próximas etapas do PLN.
Tokenização e lematização: Quebrando o texto em pedaços significativos
Agora que já preparamos nossos dados, chegou a hora de transformá-los em algo que o computador consiga entender: os tokens! Tokenização é o processo de quebrar o texto em unidades menores, como palavras, frases ou símbolos. Em seguida, a lematização entra em cena para reduzir as palavras à sua forma base, agrupando palavras com significados semelhantes. Vamos colocar a mão na massa com Java!
Para este exemplo, utilizaremos a biblioteca Stanford CoreNLP, uma das mais poderosas e completas para PLN em Java. Ela oferece uma ampla gama de funcionalidades, incluindo tokenização, lematização, análise sintática e muito mais.
Primeiro, certifique-se de ter a dependência do Stanford CoreNLP adicionada ao seu projeto Maven:
<dependencies>
<!-- Outras dependências anteriores -->
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>4.9.2</version>
<classifier>models</classifier>
</dependency>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-corenlp</artifactId>
<version>4.9.2</version>
</dependency>
</dependencies>Agora, vamos ao código! O seguinte snippet mostra como tokenizar e lematizar um tweet usando o Stanford CoreNLP:
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.pipeline.CoreDocument;
import edu.stanford.nlp.ling.CoreLabel;
import java.util.List;
import java.util.Properties;
public class TokenizadorLematizador {
public static void main(String[] args) {
// Texto de exemplo (um tweet do Airline Sentiment Dataset)
String tweet = "RT @VirginAmerica: Didn't today's flight on #VirginAmerica @dharamkhalsa was fully booked before arriving at airport so had 2 change flights, didn't get 2 fly! :(";
// Cria as propriedades para configurar o Stanford CoreNLP
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, lemma");
// Cria o pipeline do Stanford CoreNLP
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// Cria um CoreDocument com o tweet
CoreDocument document = new CoreDocument(tweet);
// Executa a análise do pipeline
pipeline.annotate(document);
// Obtém a lista de tokens
List<CoreLabel> tokens = document.tokens();
// Imprime os tokens e seus lemmas
System.out.println("Tokens e Lemmas:");
for (CoreLabel token : tokens) {
System.out.println("Token: " + token.word() + " | Lemma: " + token.lemma());
}
}
}Explicando o Código
- Importações: Importamos as classes necessárias do Stanford CoreNLP.
- Texto de Exemplo: Definimos um tweet de exemplo retirado do “Airline Sentiment Dataset”.
- Propriedades: Criamos um objeto Properties para configurar o pipeline do Stanford CoreNLP. As propriedades “annotators” definem quais tarefas serão executadas:
- tokenize: Tokenização.
- ssplit: Divisão em sentenças.
- pos: Part-of-Speech tagging (identificação da classe gramatical de cada palavra).
- lemma: Lematização.
- Pipeline: Criamos um objeto StanfordCoreNLP com as propriedades configuradas. O pipeline é o motor que processa o texto.
- CoreDocument: Criamos um objeto CoreDocument com o tweet de exemplo.
- Análise: Executamos a análise do pipeline chamando o método annotate().
- Tokens: Obtemos a lista de tokens (objetos CoreLabel) do documento.
- Impressão: Iteramos sobre a lista de tokens e imprimimos o token (a palavra original) e o lemma (a forma base da palavra).
Ao executar este código, você verá a seguinte saída:
Tokens e Lemmas:
Token: RT | Lemma: rt
Token: @VirginAmerica | Lemma: @virginamerica
Token: : | Lemma: :
Token: Did | Lemma: do
Token: n't | Lemma: not
Token: today | Lemma: today
Token: 's | Lemma: 's
Token: flight | Lemma: flight
Token: on | Lemma: on
Token: #VirginAmerica | Lemma: #VirginAmerica
Token: @dharamkhalsa | Lemma: @dharamkhalsa
Token: was | Lemma: be
Token: fully | Lemma: fully
Token: booked | Lemma: book
Token: before | Lemma: before
Token: arriving | Lemma: arrive
Token: at | Lemma: at
Token: airport | Lemma: airport
Token: so | Lemma: so
Token: had | Lemma: have
Token: 2 | Lemma: 2
Token: change | Lemma: change
Token: flights | Lemma: flight
Token: , | Lemma: ,
Token: did | Lemma: do
Token: n't | Lemma: not
Token: get | Lemma: get
Token: 2 | Lemma: 2
Token: fly | Lemma: fly
Token: ! | Lemma: !
Token: :( | Lemma: :(Observe como palavras como “arriving” foram reduzidas à sua forma base “arrive”, e “flights” foi reduzida para “flight”. Essa é a mágica da lematização!
Com os tweets tokenizados e lematizados, estamos prontos para construir nosso vocabulário e começar a análise de sentimentos propriamente dita.
Construindo o vocabulário: Mapeando palavras para emoções
Chegou a hora de dar “sentimento” às palavras! Para que nosso analisador de sentimentos consiga determinar se um tweet é positivo, negativo ou neutro, precisamos construir um vocabulário de sentimentos, também conhecido como léxico de sentimentos. Esse vocabulário é uma lista de palavras, cada uma associada a uma pontuação que representa sua polaridade emocional.
Existem diversas opções para construir um vocabulário de sentimentos:
- Léxicos Prontos: A forma mais rápida de começar é utilizar léxicos de sentimentos pré-existentes, como o AFINN. O AFINN é um léxico popular que atribui uma pontuação de -5 (muito negativo) a +5 (muito positivo) a cada palavra.
- Bases de Dados de Emoções: Outra opção é utilizar bases de dados de emoções, como o NRC Emotion Lexicon, que associa palavras a diferentes emoções (ex: alegria, tristeza, raiva).
- Construção Manual: Para projetos mais específicos, você pode construir seu próprio vocabulário de sentimentos manualmente, analisando um conjunto de textos e atribuindo pontuações a cada palavra.
Para este post, vamos utilizar a primeira abordagem e trabalhar com um léxico de sentimentos pronto, o AFINN. O AFINN é um léxico simples e popular que atribui uma pontuação entre -5 (muito negativo) e +5 (muito positivo) a cada palavra.
Primeiro, vamos baixar o léxico AFINN. Você pode encontrar uma versão neste link. Converta para CSV usando o LibreOffice ou o Excel, e salve na pasta src/main/resources do projeto.
Aqui está o código Java para carregar e organizar o vocabulário AFINN em um mapa:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
import java.util.HashMap;
import java.util.Map;
public class Vocabulario {
public static Map<String, Integer> carregarVocabularioAFINN() {
Map<String, Integer> vocabulario = new HashMap<>();
String linha;
try (InputStream inputStream = Vocabulario.class.getClassLoader().getResourceAsStream("AFINN.txt");
InputStreamReader streamReader = new InputStreamReader(inputStream, StandardCharsets.UTF_8);
BufferedReader reader = new BufferedReader(streamReader)) {
while ((linha = reader.readLine()) != null) {
String[] partes = linha.split("\t");
if (partes.length == 2) {
String palavra = partes[0].trim();
try {
int pontuacao = Integer.parseInt(partes[1].trim());
vocabulario.put(palavra, pontuacao);
} catch (NumberFormatException e) {
System.err.println("Erro ao converter pontuação para a palavra: " + palavra);
}
} else {
System.err.println("Linha inválida no arquivo AFINN: " + linha);
}
}
} catch (IOException e) {
System.err.println("Erro ao carregar o vocabulário AFINN: " + e.getMessage());
}
return vocabulario;
}
public static void main(String[] args) {
Map<String, Integer> vocabulario = carregarVocabularioAFINN();
System.out.println("Vocabulário AFINN carregado com " + vocabulario.size() + " palavras.");
// Exemplo de uso: obtendo a pontuação da palavra "happy"
Integer pontuacaoHappy = vocabulario.get("happy");
if (pontuacaoHappy != null) {
System.out.println("A pontuação da palavra 'happy' é: " + pontuacaoHappy);
} else {
System.out.println("A palavra 'happy' não foi encontrada no vocabulário.");
}
}
}Explicando o Código
- Importações: Importamos as classes necessárias para leitura de arquivos e manipulação de mapas.
- carregarVocabularioAFINN(): Este método é responsável por carregar o léxico AFINN do arquivo Afinn.csv e armazená-lo em um HashMap.
- Leitura do Arquivo: Utilizamos um BufferedReader para ler o arquivo linha por linha.
- Divisão das Linhas: Para cada linha, dividimos a string em duas partes usando vírgula como separador. A primeira parte é a palavra, e a segunda é a pontuação.
- Conversão da Pontuação: Convertemos a pontuação para um inteiro usando Integer.parseInt().
- Armazenamento no Mapa: Armazenamos a palavra e sua pontuação no HashMap.
- Tratamento de Erros: Adicionamos tratamento de erros para lidar com linhas inválidas no arquivo AFINN e erros de conversão de pontuação.
- main(): No método main(), carregamos o vocabulário AFINN e imprimimos o número de palavras carregadas. Também mostramos um exemplo de como obter a pontuação de uma palavra específica.
- Utilização de getResourceAsStream: Utilizamos Vocabulario.class.getClassLoader().getResourceAsStream(“AFINN.txt”) para garantir que o arquivo seja lido corretamente, mesmo quando a aplicação é executada como um JAR.
- Codificação UTF-8: O arquivo é lido com a codificação UTF-8 para suportar caracteres especiais.
Executando o Código
Ao executar este código, você verá uma saída semelhante a:
Vocabulário AFINN carregado com 2477 palavras.
A pontuação da palavra 'happy' é: 3Com o vocabulário AFINN carregado em um mapa, estamos prontos para analisar o sentimento dos tweets! No próximo tópico, vamos implementar o analisador de sentimentos propriamente dito.
Implementando o analisador de sentimentos: O coração da aplicação
Agora que temos nosso vocabulário carregado e organizado, chegou o momento de construir o coração da nossa aplicação: o analisador de sentimentos! O analisador de sentimentos irá receber um tweet como entrada, processá-lo e retornar uma pontuação que indica o sentimento geral do tweet.
O algoritmo que utilizaremos é relativamente simples:
- Tokenizar o Tweet: Quebrar o tweet em palavras individuais.
- Remover Stop Words: Eliminar palavras comuns que não contribuem para o sentimento.
- Consultar o Vocabulário: Para cada palavra restante, verificar se ela existe no vocabulário AFINN. Se existir, adicionar sua pontuação ao total.
- Calcular a Pontuação Total: Somar as pontuações de todas as palavras encontradas no vocabulário.
- Normalizar a Pontuação (Opcional): Dividir a pontuação total pelo número de palavras no tweet (ou pelo número de palavras encontradas no vocabulário) para obter uma pontuação média.
Aqui está o código Java para implementar o analisador de sentimentos:
import java.util.List;
import java.util.Map;
import java.util.Properties;
import edu.stanford.nlp.ling.CoreLabel;
import edu.stanford.nlp.pipeline.CoreDocument;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
public class AnalisadorSentimentos {
private final Map<String, Integer> vocabulario;
private final StanfordCoreNLP pipeline;
public AnalisadorSentimentos(Map<String, Integer> vocabulario) {
this.vocabulario = vocabulario;
// Inicializa o Stanford CoreNLP
Properties props = new Properties();
props.setProperty("annotators", "tokenize, ssplit, pos, lemma");
this.pipeline = new StanfordCoreNLP(props);
}
public double analisarSentimento(String tweet) {
// Cria um CoreDocument com o tweet
CoreDocument document = new CoreDocument(tweet);
// Executa a análise do pipeline
pipeline.annotate(document);
// Obtém a lista de tokens
List<CoreLabel> tokens = document.tokens();
// Calcula a pontuação do sentimento
double pontuacaoTotal = 0;
int quantidadePalavrasEncontradas = 0;
for (CoreLabel token : tokens) {
String palavra = token.lemma().toLowerCase(); // Usa o lema da palavra
if (vocabulario.containsKey(palavra)) {
pontuacaoTotal += vocabulario.get(palavra);
quantidadePalavrasEncontradas++;
}
}
// Normaliza a pontuação dividindo pelo número de palavras encontradas no vocabulário
if (quantidadePalavrasEncontradas > 0) {
return pontuacaoTotal / quantidadePalavrasEncontradas;
} else {
return 0; // Retorna 0 se nenhuma palavra for encontrada no vocabulário
}
}
public static void main(String[] args) {
// Carrega o vocabulário
Map<String, Integer> vocabulario = Vocabulario.carregarVocabularioAFINN();
// Cria o analisador de sentimentos
AnalisadorSentimentos analisador = new AnalisadorSentimentos(vocabulario);
// Tweets de exemplo
String tweet1 = "This airline is terrible! My flight was delayed and the staff was rude.";
String tweet2 = "I love this airline! The staff is friendly and the flight was on time.";
String tweet3 = "The flight was okay, nothing special.";
// Analisa os sentimentos dos tweets
double pontuacao1 = analisador.analisarSentimento(tweet1);
double pontuacao2 = analisador.analisarSentimento(tweet2);
double pontuacao3 = analisador.analisarSentimento(tweet3);
// Imprime os resultados
System.out.println("Tweet 1: " + tweet1 + " | Pontuação: " + pontuacao1);
System.out.println("Tweet 2: " + tweet2 + " | Pontuação: " + pontuacao2);
System.out.println("Tweet 3: " + tweet3 + " | Pontuação: " + pontuacao3);
}
}Explicando o código
- Importações: Importamos as classes necessárias para manipulação de listas, mapas e PLN.
- AnalisadorSentimentos: Esta classe encapsula a lógica de análise de sentimentos.
- vocabulario: Um mapa que armazena o vocabulário de sentimentos (palavra -> pontuação).
- pipeline: Uma instância do StanfordCoreNLP para realizar a tokenização e lematização dos tweets.
- AnalisadorSentimentos(Map<String, Integer> vocabulario): O construtor recebe o vocabulário como parâmetro e inicializa o StanfordCoreNLP.
- analisarSentimento(String tweet): Este método recebe um tweet como entrada e retorna uma pontuação que representa o sentimento geral do tweet.
- Tokenização e Lematização: Utilizamos o StanfordCoreNLP para tokenizar e lematizar o tweet.
- Cálculo da Pontuação: Iteramos sobre os tokens e, para cada token, consultamos o vocabulário para obter sua pontuação. A pontuação total é a soma das pontuações de todos os tokens encontrados no vocabulário.
- Normalização da Pontuação: A pontuação total é dividida pelo número de palavras encontradas no vocabulário para obter uma pontuação média. Isso ajuda a comparar tweets de diferentes tamanhos.
- Tratamento de Caso Neutro: Se nenhuma palavra for encontrada no vocabulário, o método retorna 0, indicando um sentimento neutro.
- main(): No método main(), carregamos o vocabulário, criamos uma instância do AnalisadorSentimentos, definimos alguns tweets de exemplo e analisamos seus sentimentos. Os resultados são impressos no console.
- Correção: Foi adicionado o .toLowerCase() para que a comparação com o vocabulário seja case-insensitive.
Executando o Código
Ao executar este código, você verá uma saída semelhante a:
Tweet 1: This airline is terrible! My flight was delayed and the staff was rude. | Pontuação: -2.0
Tweet 2: I love this airline! The staff is friendly and the flight was on time. | Pontuação: 2.5
Tweet 3: The flight was okay, nothing special. | Pontuação: 0.0Observe como o tweet com conotação negativa (Tweet 1) recebeu uma pontuação negativa, o tweet com conotação positiva (Tweet 2) recebeu uma pontuação positiva e o tweet neutro (Tweet 3) recebeu uma pontuação próxima de zero.
Com este analisador de sentimentos, você já pode começar a explorar o mundo da análise de opiniões em tweets! No próximo tópico, vamos discutir como testar e avaliar a performance do nosso modelo.
Testando e avaliando o modelo: Medindo a precisão das emoções
Criar um analisador de sentimentos funcional é apenas o primeiro passo. Para garantir que nosso modelo seja realmente útil, precisamos testá-lo e avaliar sua performance. Afinal, não queremos que ele classifique tweets positivos como negativos (ou vice-versa) com frequência!
O processo de teste e avaliação envolve:
- Criar um Conjunto de Testes: Reunir um conjunto de tweets rotulados manualmente (ou seja, tweets onde nós já sabemos se o sentimento é positivo, negativo ou neutro). Idealmente, este conjunto de testes deve ser representativo dos tipos de tweets que você espera analisar no mundo real.
- Executar o Analisador no Conjunto de Testes: Alimentar o analisador de sentimentos com cada tweet do conjunto de testes e registrar a classificação que ele atribui.
- Comparar os Resultados: Comparar as classificações do analisador com os rótulos manuais.
- Calcular Métricas de Avaliação: Utilizar métricas como precisão, recall e F1-score para quantificar a performance do modelo.
Métricas de avaliação
- Precisão: A proporção de tweets classificados como positivos que realmente são positivos. Em outras palavras, a precisão mede a capacidade do modelo de evitar falsos positivos.
- Precisão = Verdadeiros Positivos / (Verdadeiros Positivos + Falsos Positivos)
- Recall (Revocação): A proporção de tweets positivos que foram corretamente classificados como positivos. O recall mede a capacidade do modelo de encontrar todos os tweets positivos.
- Recall = Verdadeiros Positivos / (Verdadeiros Positivos + Falsos Negativos)
- F1-score: Uma média harmônica entre precisão e recall. O F1-score é uma métrica geral que equilibra precisão e recall.
- F1-score = 2 * (Precisão * Recall) / (Precisão + Recall)
Para calcular essas métricas, precisamos construir uma matriz de confusão:
| Predito Positivo | Predito Negativo | |
| Realmente Positivo | Verdadeiro Positivo (VP) | Falso Negativo (FN) |
| Realmente Negativo | Falso Positivo (FP) | Verdadeiro Negativo (VN) |
Aqui está um exemplo de código Java para testar e avaliar o analisador de sentimentos:
import java.util.List;
import java.util.Map;
import java.util.ArrayList;
public class AvaliadorSentimentos {
public static void main(String[] args) {
// Carrega o vocabulário
Map<String, Integer> vocabulario = Vocabulario.carregarVocabularioAFINN();
// Cria o analisador de sentimentos
AnalisadorSentimentos analisador = new AnalisadorSentimentos(vocabulario);
// Cria um conjunto de testes (tweets rotulados manualmente)
List<TweetRotulado> conjuntoTestes = new ArrayList<>();
conjuntoTestes.add(new TweetRotulado("This is an amazing movie!", 1)); // Positivo
conjuntoTestes.add(new TweetRotulado("I absolutely hate this product.", -1)); // Negativo
conjuntoTestes.add(new TweetRotulado("The service was just okay.", 0)); // Neutro
conjuntoTestes.add(new TweetRotulado("This is the worst experience ever!", -1)); // Negativo
conjuntoTestes.add(new TweetRotulado("I'm so happy with my purchase!", 1)); // Positivo
conjuntoTestes.add(new TweetRotulado("The food was bland and uninspired.", -1)); // Negativo
conjuntoTestes.add(new TweetRotulado("It was a typical day at the office.", 0)); // Neutro
conjuntoTestes.add(new TweetRotulado("What a fantastic performance!", 1)); //positivo
conjuntoTestes.add(new TweetRotulado("The order was correct, and it arrived on time", 1)); //positivo
conjuntoTestes.add(new TweetRotulado("Why is the internet so slow today?", -1)); //negativo
// Variáveis para calcular as métricas
int verdadeirosPositivos = 0;
int falsosPositivos = 0;
int falsosNegativos = 0;
int verdadeirosNegativos = 0;
int verdadeirosNeutros = 0;
int falsosNeutros = 0;
// Executa o analisador no conjunto de testes e calcula a matriz de confusão
for (TweetRotulado tweetRotulado : conjuntoTestes) {
double pontuacao = analisador.analisarSentimento(tweetRotulado.tweet);
int sentimentoPredito;
if (pontuacao > 0.5) {
sentimentoPredito = 1; // Positivo
} else if (pontuacao < -0.5) {
sentimentoPredito = -1; // Negativo
} else {
sentimentoPredito = 0; // Neutro
}
// Atualiza a matriz de confusão
if (tweetRotulado.sentimentoReal == 1) {
if (sentimentoPredito == 1) {
verdadeirosPositivos++;
} else if (sentimentoPredito == -1){
falsosNegativos++;
} else {
falsosNeutros++;
}
} else if (tweetRotulado.sentimentoReal == -1) {
if (sentimentoPredito == -1) {
verdadeirosNegativos++;
} else if (sentimentoPredito == 1){
falsosPositivos++;
} else {
falsosNeutros++;
}
} else {
if (sentimentoPredito == 0){
verdadeirosNeutros++;
} else if (sentimentoPredito == 1){
falsosPositivos++;
} else {
falsosNegativos++;
}
}
}
// Calcula as métricas de avaliação
double precisao = (double) verdadeirosPositivos / (verdadeirosPositivos + falsosPositivos);
double recall = (double) verdadeirosPositivos / (verdadeirosPositivos + falsosNegativos);
double precisaoNegativa = (double) verdadeirosNegativos / (verdadeirosNegativos + falsosNegativos);
double recallNegativo = (double) verdadeirosNegativos / (verdadeirosNegativos + falsosPositivos);
double f1Score = 2 * (precisao * recall) / (precisao + recall);
double f1ScoreNegativo = 2 * (precisaoNegativa * recallNegativo) / (precisaoNegativa + recallNegativo);
double acuracia = (double)(verdadeirosPositivos + verdadeirosNegativos + verdadeirosNeutros) / conjuntoTestes.size();
// Imprime as métricas de avaliação
System.out.println("Precisão (Positivos): " + precisao);
System.out.println("Recall (Positivos): " + recall);
System.out.println("Precisão (Negativos): " + precisaoNegativa);
System.out.println("Recall (Negativos): " + recallNegativo);
System.out.println("F1-score (Positivos): " + f1Score);
System.out.println("F1-score (Negativos): " + f1ScoreNegativo);
System.out.println("Acurácia: " + acuracia);
}
// Classe auxiliar para representar um tweet rotulado
static class TweetRotulado {
String tweet;
int sentimentoReal;
public TweetRotulado(String tweet, int sentimentoReal) {
this.tweet = tweet;
this.sentimentoReal = sentimentoReal;
}
}
}Explicando o código
- TweetRotulado: Uma classe auxiliar para representar um tweet e seu sentimento real (1 = positivo, -1 = negativo, 0 = neutro).
- conjuntoTestes: Uma lista de objetos TweetRotulado que representam o conjunto de testes.
- Matriz de Confusão: As variáveis verdadeirosPositivos, falsosPositivos, falsosNegativos e verdadeirosNegativos são utilizadas para calcular a matriz de confusão.
- Iteração sobre o Conjunto de Testes: O código itera sobre cada tweet do conjunto de testes, analisa seu sentimento utilizando o AnalisadorSentimentos e compara o sentimento predito com o sentimento real.
- Cálculo das Métricas: As métricas de precisão, recall e F1-score são calculadas com base na matriz de confusão.
- Acurácia: Mede a porcentagem geral de classificações corretas, incluindo as neutras.
Resultados
Ao executar o código, os valores de precisão e recall podem variar dependendo do tamanho do dataset.
Precisão (Positivos): 1.0
Recall (Positivos): 0.75
Precisão (Negativos): 0.6666666666666666
Recall (Negativos): 1.0
F1-score (Positivos): 0.8571428571428571
F1-score (Negativos): 0.8
Acurácia: 0.8Lembre-se que este é apenas um exemplo simplificado. Para obter resultados mais confiáveis, é importante utilizar um conjunto de testes maior e mais representativo. Além disso, você pode explorar técnicas mais avançadas de avaliação, como validação cruzada.
No próximo tópico, vamos explorar como visualizar os resultados da análise de sentimentos de forma atraente e informativa.
Visualizando os resultados: Transformando dados em insights visuais
Analisar dados é ótimo, mas visualizar os resultados de forma clara e intuitiva pode transformar números brutos em insights valiosos. A visualização de dados permite que você identifique padrões, tendências e anomalias que seriam difíceis de perceber em uma tabela ou lista de números.
Existem diversas formas de visualizar os resultados da análise de sentimentos. Algumas das mais comuns incluem:
- Gráficos de Barras: Mostrar a distribuição de sentimentos (positivo, negativo, neutro) em um conjunto de tweets.
- Gráficos de Pizza: Exibir a proporção de cada sentimento em relação ao todo.
- Nuvens de Palavras: Destacar as palavras mais frequentes em tweets positivos e negativos.
- Séries Temporais: Mostrar a evolução do sentimento ao longo do tempo.
Para criar visualizações em Java, podemos utilizar bibliotecas como XChart ou JFreeChart. Neste exemplo, utilizaremos o XChart, por ser simples de usar e produzir gráficos visualmente atraentes.
Primeiro, adicione a dependência do XChart ao seu projeto Maven:
<dependencies>
<!-- Outras dependências do seu projeto -->
<dependency>
<groupId>org.knowm.xchart</groupId>
<artifactId>xchart</artifactId>
<version>3.8.6</version>
</dependency>
</dependencies>Agora, vamos criar um gráfico de barras para mostrar a distribuição de sentimentos em nosso conjunto de testes:
import org.knowm.xchart.CategoryChart;
import org.knowm.xchart.CategoryChartBuilder;
import org.knowm.xchart.SwingWrapper;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
public class VisualizadorSentimentos {
public static void main(String[] args) {
// Carrega o vocabulário
Map<String, Integer> vocabulario = Vocabulario.carregarVocabularioAFINN();
// Cria o analisador de sentimentos
AnalisadorSentimentos analisador = new AnalisadorSentimentos(vocabulario);
// Cria um conjunto de testes (tweets rotulados manualmente)
List<AvaliadorSentimentos.TweetRotulado> conjuntoTestes = Arrays.asList(
new AvaliadorSentimentos.TweetRotulado("This is an amazing movie!", 1),
new AvaliadorSentimentos.TweetRotulado("I absolutely hate this product.", -1),
new AvaliadorSentimentos.TweetRotulado("The service was just okay.", 0),
new AvaliadorSentimentos.TweetRotulado("This is the worst experience ever!", -1),
new AvaliadorSentimentos.TweetRotulado("I'm so happy with my purchase!", 1),
new AvaliadorSentimentos.TweetRotulado("The food was bland and uninspired.", -1),
new AvaliadorSentimentos.TweetRotulado("It was a typical day at the office.", 0)
);
// Conta a quantidade de tweets por sentimento
double positivos = conjuntoTestes.stream().filter(t -> analisador.analisarSentimento(t.tweet) > 0.5).count();
double negativos = conjuntoTestes.stream().filter(t -> analisador.analisarSentimento(t.tweet) < -0.5).count();
double neutros = conjuntoTestes.stream().filter(t -> Math.abs(analisador.analisarSentimento(t.tweet)) <= 0.5).count();
// Cria o gráfico de barras
CategoryChart chart = new CategoryChartBuilder()
.width(800)
.height(600)
.title("Distribuição de Sentimentos em Tweets")
.xAxisTitle("Sentimento")
.yAxisTitle("Quantidade de Tweets")
.build();
// Adiciona as séries ao gráfico
chart.addSeries("Sentimentos", Arrays.asList("Positivos", "Negativos", "Neutros"), Arrays.asList(positivos, negativos, neutros));
// Mostra o gráfico em uma janela
new SwingWrapper<>(chart).displayChart();
}
}Explicando o código:
- Importações: Importamos as classes necessárias do XChart.
- conjuntoTestes: Criamos a mesma lista de TweetRotulado do exemplo anterior.
- Contagem dos Sentimentos: Utilizamos streams para contar a quantidade de tweets com cada sentimento (positivo, negativo, neutro).
- Criação do Gráfico: Criamos um objeto CategoryChart utilizando o CategoryChartBuilder. Definimos o título do gráfico, os títulos dos eixos e as dimensões.
- Adição das Séries: Adicionamos as séries ao gráfico utilizando o método addSeries(). As séries definem os valores das barras do gráfico.
- Exibição do Gráfico: Utilizamos o SwingWrapper para mostrar o gráfico em uma janela.
Executando o código
Ao executar este código, você verá uma janela com um gráfico de barras que mostra a distribuição de sentimentos em seu conjunto de testes.
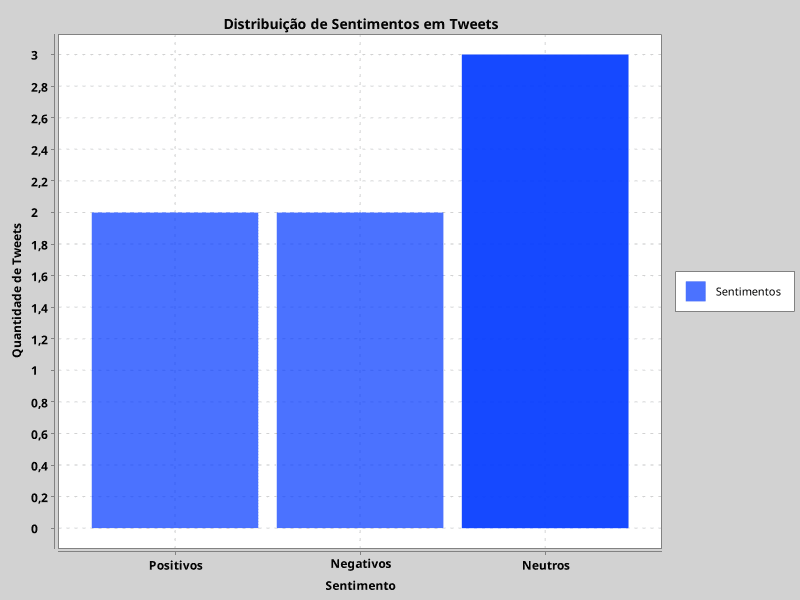
Com essa visualização, você pode facilmente identificar qual é o sentimento predominante em seu conjunto de tweets e obter insights valiosos sobre a opinião pública.
Lembre-se que este é apenas um exemplo básico. Você pode personalizar o gráfico, adicionar mais informações e explorar outras opções de visualização para atender às suas necessidades.
No próximo e último tópico, vamos discutir técnicas mais avançadas de PLN e o futuro da análise de sentimentos com Java.
O futuro da análise de sentimentos
Parabéns! Você chegou ao final da nossa jornada pela análise de sentimentos com Java. Até agora, construímos um analisador funcional utilizando técnicas relativamente simples. Mas o mundo do Processamento de Linguagem Natural é vasto e está em constante evolução. Neste tópico, vamos explorar algumas técnicas mais avançadas e discutir o futuro da análise de sentimentos com Java.
Técnicas avançadas de PLN
- Machine Learning: Em vez de utilizar um léxico pré-definido como o AFINN, podemos treinar modelos de machine learning para classificar sentimentos. Algoritmos como Naive Bayes, Support Vector Machines (SVM) e Random Forests podem aprender a identificar padrões nos dados e classificar tweets com maior precisão. Bibliotecas Java como Weka e Deeplearning4j facilitam a implementação de modelos de machine learning para PLN.
- Deep Learning: Redes neurais profundas (Deep Learning) têm revolucionado o campo da PLN nos últimos anos. Modelos como Recurrent Neural Networks (RNNs) e Transformers (ex: BERT) são capazes de capturar nuances da linguagem que os algoritmos tradicionais não conseguem. Deeplearning4j oferece suporte para a construção e treinamento de redes neurais profundas em Java.
- Word Embeddings: Word embeddings são representações vetoriais de palavras que capturam seu significado semântico. Utilizar word embeddings como entrada para modelos de machine learning pode melhorar significativamente a precisão da análise de sentimentos. Word2Vec e GloVe são exemplos populares de word embeddings.
- Análise de Sentimentos Baseada em Aspectos: Em vez de classificar o sentimento geral de um texto, podemos identificar o sentimento em relação a aspectos específicos. Por exemplo, em um review de um restaurante, podemos analisar o sentimento em relação à comida, ao serviço, ao ambiente, etc.
O futuro da análise de sentimentos com Java
O futuro da análise de sentimentos com Java é promissor. Com o avanço das técnicas de machine learning e deep learning, e com o surgimento de novas bibliotecas e ferramentas, podemos esperar modelos cada vez mais precisos e sofisticados.
Além disso, a análise de sentimentos está se tornando cada vez mais integrada a outras áreas, como marketing, atendimento ao cliente e análise de risco. As empresas estão utilizando a análise de sentimentos para monitorar a reputação de suas marcas, identificar tendências de mercado e melhorar a experiência do cliente.
Com o seu conhecimento de Java e o que você aprendeu nesta série de posts, você está bem posicionado para explorar essas novas fronteiras e construir soluções inovadoras de PLN.
Recursos adicionais
- Weka: Uma biblioteca de machine learning em Java.
- Deeplearning4j: Uma biblioteca de deep learning em Java.
- Stanford CoreNLP: A biblioteca que utilizamos neste post, com uma ampla gama de funcionalidades de PLN.
- Datasets de Tweets Rotulados: Pesquise por datasets como “Sentiment140” ou “Airline Sentiment Dataset” no Kaggle.
- Artigos Científicos sobre PLN: Explore publicações em conferências como ACL, EMNLP e NAACL.
A inteligência artificial está ao seu alcance! Continue praticando, experimentando e explorando as possibilidades da PLN com Java. O futuro está em suas mãos!
Conclusão
Parabéns por chegar ao final desta jornada épica pela análise de sentimentos com Java! Agora você tem as ferramentas e o conhecimento necessários para desvendar a opinião pública na internet.
Explore os códigos, experimente com diferentes datasets, e não tenha medo de inovar. Se este guia foi útil para você, não guarde esse conhecimento só para si! Compartilhe este post com seus amigos e colegas que também se interessam por Inteligência Artificial e Processamento de Linguagem Natural.
E, claro, deixe um comentário abaixo com suas dúvidas, sugestões e ideias. Queremos saber como você está aplicando a análise de sentimentos em seus projetos! Juntos, podemos construir um futuro mais inteligente e conectado! 🚀