

Olá, pessoal do FlipBits! Sejam bem-vindos de volta ao nosso laboratório de ideias, onde desvendamos os mistérios do universo da Inteligência Artificial e do Machine Learning, um bit de cada vez! E hoje, vamos mergulhar em um tópico que, honestamente, me tira o sono (de um jeito bom, juro!): a explicabilidade em IA.
Sabe aquela sensação de que você está conversando com alguém super inteligente, mas que fala por enigmas? Tipo, “confie em mim, eu sei o que estou fazendo”? Pois é, muitas vezes é assim que nos sentimos quando lidamos com alguns dos nossos modelos de Machine Learning mais poderosos. Eles nos dão respostas espetaculares, mas quando perguntamos “por que?”, a resposta é um silêncio eloquente. E isso, meus amigos, é um problema que precisamos resolver.
A enigmática caixa-preta: O que é e por que nos preocupa?
Imagine que você é um juiz e precisa decidir se concede um empréstimo. Um algoritmo super sofisticado te diz: “Não conceda o empréstimo para o João”. Você, como juiz, pergunta: “Mas por quê? O João tem bom histórico, paga as contas em dia!”. E o algoritmo responde: “Apenas confie no meu modelo, ele é 99% preciso!”.
No mundo real, essa situação é inaceitável, certo? Precisamos de justificativas, de transparência. E é exatamente isso que a “caixa-preta” representa: modelos de Machine Learning complexos (como redes neurais profundas) que são excelentes em prever, mas péssimos em explicar como chegaram a essa previsão.
Pense em um carro autônomo. Ele decide virar à direita. Legal, mas por que? Porque viu um pedestre? Um obstáculo? Um cocô de pombo no meio da rua? A gente precisa saber! Em áreas críticas como saúde, finanças ou justiça, essa falta de explicabilidade não é apenas incômoda; é perigosa, eticamente questionável e, muitas vezes, ilegal!
XAI: O Sherlock Holmes da Inteligência Artificial
É aí que entra em cena a XAI, ou Explicable Artificial Intelligence (Inteligência Artificial Explicável). A XAI não é um algoritmo novo, mas sim um campo de estudo e um conjunto de ferramentas e técnicas cujo objetivo principal é tornar os modelos de IA mais compreensíveis para nós, humanos. É como dar uma lupa para o nosso “detetive” interno investigar o que acontece dentro da caixa-preta.
A ideia é transformar aquele “confie em mim” em um “deixe-me explicar como cheguei a essa conclusão”. Isso nos permite:
- Construir Confiança: Se entendemos como a IA funciona, confiamos mais nela. Simples assim.
- Identificar Erros e Vícios: Às vezes, o modelo toma decisões erradas porque aprendeu vieses nos dados. A XAI nos ajuda a encontrar essas “manchas” no aprendizado.
- Garantir Conformidade: Regulamentações (como a GDPR na Europa) exigem o “direito à explicação” para decisões automatizadas.
- Melhorar o Modelo: Entender o porquê de um modelo funcionar (ou não) nos dá insights para aprimorá-lo.
Ferramentas na maleta do detetive XAI
Existem diversas abordagens para tornar um modelo explicável. Vamos dar uma olhada em duas das mais populares e que funcionam para quase qualquer modelo (são agnósticas ao modelo, como dizemos na linguagem técnica): LIME e SHAP.
LIME (Local Interpretable Model-agnostic Explanations): O olhar local
Pense no LIME como um detetive que foca em um único caso por vez. Ele não se importa com a história inteira da máfia, só quer saber por que aquela decisão específica foi tomada para aquela entrada de dados.
Como funciona a mágica do LIME?
- Ele pega uma previsão do seu modelo (por exemplo, “essa imagem é um gato”).
- Cria variações dessa imagem (gato com bigodes borrados, gato com orelha cortada, etc.).
- Usa seu modelo para prever cada uma dessas variações.
- Treina um modelo mais simples e explicável (como uma regressão linear ou uma árvore de decisão) que se aproxima das previsões do modelo original somente para aquelas variações próximas da original.
- Como o modelo simples é fácil de entender, ele pode te dizer quais características da imagem original foram mais importantes para o seu modelo complexo classificá-la como “gato”.
É como se o LIME dissesse: “Para essa imagem específica de gato, foram os olhos, os bigodes e o formato da cabeça que mais pesaram na decisão do modelo”.
Vamos simular um problema de classificação de texto onde nosso modelo prediz se um tweet é positivo ou negativo.
import pandas as pd
import shap
from lime.lime_text import LimeTextExplainer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
# --- Seção de Preparação de Dados e Treinamento do Modelo ---
# 1. Preparando os Dados (apenas um exemplo simples)
# Criamos um pequeno conjunto de dados de textos e seus respectivos sentimentos.
# Usamos 1 para sentimento positivo e 0 para negativo.
data = {
'text': [
"A IA é incrível e vai mudar o mundo!",
"Esse modelo é muito lento e cheio de bugs.",
"Adorei o artigo do FlipBits, super claro!",
"Que decepção, a performance está horrível.",
"Machine Learning é fascinante e promissor."
],
'sentiment': [1, 0, 1, 0, 1] # 1 para positivo, 0 para negativo
}
df = pd.DataFrame(data) # Convertemos o dicionário em um DataFrame do Pandas
# 2. Treinando um Modelo Simples de Classificação de Texto
# Inicializamos o TF-IDF Vectorizer. Ele converte os textos em vetores numéricos
# (representações esparsas) que o modelo de Machine Learning consegue entender.
# "fit_transform" aprende o vocabulário e transforma os textos.
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df['text']) # Variáveis de entrada (textos vetorizados)
y = df['sentiment'] # Variável de saída (sentimento)
# Criamos e treinamos um modelo de Regressão Logística, que é um classificador linear.
# O `random_state` garante que os resultados sejam reproduzíveis.
model = LogisticRegression(random_state=42)
model.fit(X, y) # Treinamos o modelo com os dados vetorizados e os sentimentos
# Definimos os nomes das classes para facilitar a interpretação dos resultados.
class_names = ['Negativo', 'Positivo']
# Obtemos os nomes das features (palavras) do vetorizador.
# Isso será útil para associar as contribuições de SHAP e LIME às palavras.
feature_names = vectorizer.get_feature_names_out()
# --- Seção de Teste com LIME ---
print("--- Teste LIME ---")
# 3. Utilizando o LIME para Explicar uma Predição Específica
# Inicializamos o LimeTextExplainer. Ele é projetado especificamente para explicar
# classificadores de texto e exige os nomes das classes.
explainer_lime = LimeTextExplainer(class_names=class_names)
# Escolhemos um texto específico para o LIME explicar.
text_to_explain_lime = "Adorei o artigo do FlipBits, super claro!"
# Definimos a função de predição de probabilidades para o LIME.
# O LIME passa textos (perturbados) para essa função.
# Portanto, a função precisa vetorizar internamente os textos antes de passá-los ao modelo.
def predict_proba_func_lime(texts):
# Garante que 'texts' é uma lista, mesmo que uma única string seja passada.
if isinstance(texts, str):
texts = [texts]
# Converte cada item da lista para string para evitar erros no vetorizador,
# caso o LIME passe algum tipo de dado inesperado (ex: numpy array em versões mais antigas).
processed_texts = [str(text) for text in texts]
# Retorna as probabilidades de cada classe (Negativo, Positivo) para os textos.
return model.predict_proba(vectorizer.transform(processed_texts))
# Geramos a explicação LIME para a instância de texto escolhida.
# - text_to_explain_lime: o texto a ser explicado.
# - predict_proba_func_lime: a função de predição do nosso modelo.
# - num_features: o número de palavras mais importantes a serem destacadas na explicação.
# - labels: a(s) classe(s) para as quais queremos a explicação (aqui, a classe Positivo, índice 1).
explanation_lime = explainer_lime.explain_instance(
text_to_explain_lime,
predict_proba_func_lime,
num_features=5,
labels=[1]
)
# Exibimos os resultados do LIME no console.
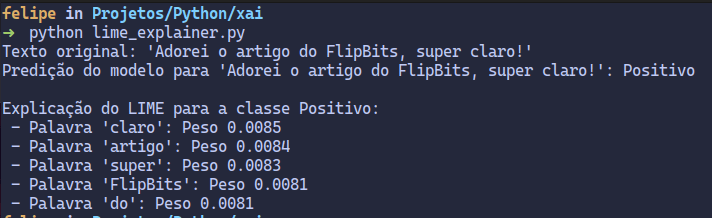
print(f"Texto original (LIME): '{text_to_explain_lime}'")
# Predizimos e exibimos o sentimento original do texto.
print(f"Predição do modelo (LIME): {class_names[model.predict(vectorizer.transform([text_to_explain_lime]))[0]]}")
print("\nExplicação do LIME para a classe Positivo:")
# Iteramos sobre as palavras mais importantes e seus pesos (contribuições) para a classe Positivo.
for word, weight in explanation_lime.as_list(label=1):
print(f" - Palavra '{word}': Peso {weight:.4f}")
# Separador visual para diferenciar as seções LIME e SHAP.
print("\n" + "="*40 + "\n")
# Para visualização interativa do LIME em ambientes como Jupyter Notebook.
# Comenta-se para evitar erro se não estiver em um notebook.
# explanation_lime.show_in_notebook(text=True)O que o código está fazendo?
- Dados e Modelo: Criamos um dataset simples de tweets e seus sentimentos, e treinamos um modelo de Regressão Logística para classificá-los como positivos ou negativos.
predict_proba_func: O LIME precisa de uma função que, dada uma lista de textos, retorne a probabilidade de cada texto pertencer a cada uma das classes. Nossa função faz exatamente isso, transformando os textos em vetores numéricos antes de passá-los ao modelo.LimeTextExplainer: Inicializamos o explicador do LIME para texto, informando os nomes das nossas classes (Positivo/Negativo).explain_instance: Aqui é onde a mágica acontece. Passamos o texto que queremos explicar, a função de predição do nosso modelo, o número de características (palavras) mais importantes que queremos ver e para qual classe queremos a explicação (neste caso, a classe “Positivo”).- Resultados: O LIME nos retorna uma lista de palavras (características) e seus pesos, indicando o quão importante cada palavra foi para a decisão do modelo naquele texto específico. Por exemplo, a palavra “Adorei” provavelmente terá um peso positivo alto para a classificação como “Positivo”.

SHAP (SHapley Additive exPlanations): A contribuição justa
Se o LIME é o detetive que foca em um caso, o SHAP é o contador forense que distribui o crédito (ou a culpa) de forma justa entre todos os “envolvidos” na decisão. Ele se baseia em um conceito da Teoria dos Jogos chamado valores de Shapley, que garantem que a contribuição de cada “jogador” (neste caso, cada característica do seu dado) para o resultado final seja distribuída de maneira equitativa.
A ideia por trás do SHAP é: para cada previsão, o SHAP calcula a contribuição de cada feature (característica) para desviar a previsão da média (ou do baseline).
É como se você tivesse uma equipe de jogadores e quisesse saber a contribuição exata de cada um para a vitória. O SHAP avalia a importância de cada jogador em todas as possíveis combinações de jogadores. Isso o torna computacionalmente mais caro, mas incrivelmente robusto e teoricamente sólido.
Vamos ver o SHAP em ação (e sim, ele é tão legal quanto o nome sugere):
Continuando com o exemplo anterior, vamos usar o SHAP para entender nosso modelo de sentimentos.
# --- Seção de Teste com SHAP ---
print("--- Teste SHAP ---")
# Para modelos lineares como LogisticRegression, o SHAP oferece o LinearExplainer,
# que é mais eficiente e preciso do que o KernelExplainer (que é mais geral, mas computacionalmente mais caro).
# O LinearExplainer é inicializado com o modelo treinado e os dados de treinamento (vetorizados)
# para estabelecer um "background" ou "baseline".
background_data_dense = X.toarray()
explainer_shap = shap.LinearExplainer(model, background_data_dense)
# Escolhemos o mesmo texto para explicar com SHAP, garantindo consistência.
idx_to_explain = 2
text_to_explain_shap = df['text'][idx_to_explain]
# Antes de passar a instância para o `explainer_shap.shap_values`,
# precisamos vetorizá-la usando o mesmo `vectorizer` que foi usado para treinar o modelo.
instance_to_explain_vectorized = vectorizer.transform([text_to_explain_shap])
# Convertemos a matriz esparsa (Sparse Matrix) da instância única para um array NumPy denso.
# Isso é crucial porque o LinearExplainer do SHAP espera dados densos para cálculos.
instance_to_explain_dense = instance_to_explain_vectorized.toarray()
# Calculamos os valores SHAP para a instância vetorizada e densa.
# Para o LinearExplainer e um modelo de classificação com múltiplas classes,
# 'shap_values' geralmente retorna um array com a forma (n_samples, n_classes, n_features)
# ou (n_features, n_classes) para uma única amostra.
# Aqui, como estamos explicando uma única amostra e o modelo tem duas classes,
# ele retorna uma lista de arrays, um array para cada classe.
# O `shap_values[1]` conterá as contribuições para a classe Positivo.
shap_values = explainer_shap.shap_values(instance_to_explain_dense)
print(f"Texto original (SHAP): '{text_to_explain_shap}'")
# Predizer e exibir o sentimento original do texto usando o modelo.
print(f"Predição do modelo (SHAP): {class_names[model.predict(vectorizer.transform([text_to_explain_shap]))[0]]}")
print("\nValores SHAP para a classe Positivo:")
# Acessamos os valores SHAP para a classe positiva (índice 1).
# `shap_values[1][0]` acessa o primeiro (e único) conjunto de contribuições
# para a classe positiva da amostra atual.
shap_contributions = list(zip(feature_names, shap_values[0, :]))
# Ordenamos as contribuições SHAP pela magnitude absoluta para ver as palavras mais influentes,
# independentemente se contribuem positiva ou negativamente.
shap_contributions.sort(key=lambda x: abs(x[1]), reverse=True)
print("Maiores contribuições SHAP para a classe Positivo (mapeado para features TF-IDF):")
# Exibimos as 10 maiores contribuições.
for word, contribution in shap_contributions[:10]:
print(f" - Palavra/Feature '{word}': Contribuição {contribution:.4f}")
# --- Visualização Interativa SHAP (para Jupyter Notebooks) ---
# Inicializa o JavaScript necessário para as visualizações interativas do SHAP.
# Comenta-se para evitar erro se não estiver em um notebook.
# shap.initjs()
# Calcula o valor esperado (expected_value) para a classe positiva.
# Este é o valor base para a predição da classe positiva, ou seja,
# a probabilidade média da classe positiva nos dados de treinamento.
# expected_value_positive_class = model.predict_proba(X).mean(axis=0)[1]
# Gera o gráfico de força (force plot) do SHAP.
# Este gráfico mostra como cada feature empurra a previsão da "expected_value"
# para o valor final da previsão da instância.
# - expected_value_positive_class: O valor base da previsão para a classe positiva.
# - shap_values[1][0]: As contribuições SHAP para a instância atual, para a classe positiva.
# - features=instance_to_explain_dense[0]: Os valores das features da instância explicada.
# - feature_names: Os nomes das features (palavras) para rotular o gráfico.
# Comenta-se para evitar erro se não estiver em um notebook.
# shap.force_plot(expected_value_positive_class, shap_values[1][0], features=instance_to_explain_dense[0], feature_names=feature_names)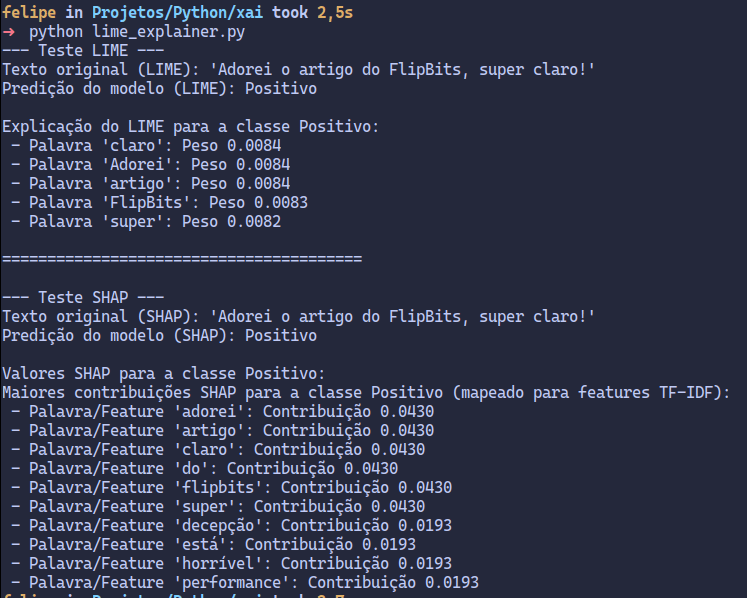
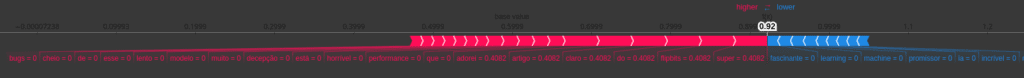
Os valores SHAP nos dizem o quanto cada palavra contribuiu para a previsão final, em relação à previsão média do modelo. Valores positivos significam que a palavra empurrou a predição em direção à classe “Positivo”, enquanto valores negativos empurraram para “Negativo”.
O futuro da IA: Não apenas inteligente, mas sábia!
A explicabilidade em IA não é apenas uma moda passageira; é uma necessidade fundamental para a adoção responsável e ética da Inteligência Artificial. Se queremos que a IA seja uma parceira confiável em decisões cruciais – desde diagnósticos médicos até avaliações de crédito –, precisamos que ela possa nos dar razões, não apenas respostas.
É como ter um colega de trabalho brilhante que não só resolve o problema, mas também te ensina o caminho das pedras. Isso não só te ajuda a confiar nele, mas também te capacita a aprender e aprimorar suas próprias habilidades.
Então, da próxima vez que você se deparar com um modelo de IA que parece um gênio misterioso, lembre-se: existem ferramentas, como LIME e SHAP, que podem te ajudar a desvendar seus segredos. E ao fazer isso, não estamos apenas construindo IAs mais transparentes, mas também um futuro onde a inteligência é não só poderosa, mas também compreensível e confiável.
E aí, o que acharam dessa viagem ao mundo da explicabilidade? Vocês já se depararam com uma “caixa-preta” que precisava ser desvendada? Compartilhem suas experiências nos comentários! E se gostaram do artigo, não se esqueçam de compartilhar com seus amigos e ajudar a espalhar a palavra sobre a importância da IA explicável. Afinal, conhecimento compartilhado é conhecimento ampliado, certo? 😉