

Imagine um mundo onde seus aplicativos Java pudessem “enxergar” e interpretar o mundo ao seu redor. Um mundo onde sistemas pudessem identificar objetos em imagens, reconhecer rostos, diagnosticar doenças com base em exames médicos e até mesmo auxiliar carros autônomos a navegar pelas ruas. Esse mundo não é mais ficção científica: é a realidade da Visão Computacional em Java.
A Visão Computacional, também conhecida como Computer Vision, é um campo fascinante da Inteligência Artificial que se dedica a desenvolver técnicas e algoritmos que permitem aos computadores “ver” e interpretar imagens e vídeos, de forma similar à visão humana. E ao combinarmos essa tecnologia com o poder e a versatilidade da linguagem Java, abrimos um universo de possibilidades para criar aplicações inteligentes e inovadoras.
Neste post, vamos embarcar em uma aventura emocionante para construir um classificador de imagens que consegue distinguir entre gatos e cachorros utilizando Java e Deep Learning! Prepare-se para aprender a carregar e pré-processar imagens, construir e treinar redes neurais convolucionais (CNNs) e avaliar a performance do seu modelo. E o melhor de tudo: este é apenas o começo! Com o conhecimento que você adquirirá aqui, estará pronto para explorar outras aplicações incríveis da Visão Computacional em Java e construir um futuro onde as máquinas realmente podem “ver” o mundo. Vamos lá!
O que é Visão Computacional? Uma introdução acessível
A Visão Computacional (ou Computer Vision) é um campo da Inteligência Artificial que busca dotar computadores e sistemas com a capacidade de “ver” e interpretar o mundo visual, assim como os seres humanos. Mas o que isso significa na prática?
Enquanto nós, humanos, utilizamos nossos olhos e cérebro para perceber, interpretar e dar sentido às imagens ao nosso redor, a Visão Computacional utiliza câmeras, sensores e algoritmos para realizar tarefas semelhantes. O objetivo é permitir que as máquinas extraiam informações úteis de imagens e vídeos, automatizando tarefas que antes exigiam a intervenção humana.
As aplicações da Visão Computacional são vastíssimas e estão presentes em diversas áreas:
- Medicina: Diagnóstico de doenças através de análise de imagens médicas (raio-x, ressonância magnética, tomografia).
- Indústria: Inspeção de qualidade em linhas de produção, identificação de defeitos em produtos.
- Segurança: Reconhecimento facial em sistemas de vigilância, detecção de intrusos em áreas restritas.
- Automobilística: Assistência à direção em carros, reconhecimento de placas de trânsito, navegação autônoma.
- Agricultura: Monitoramento de plantações, identificação de pragas e doenças em lavouras.
- Varejo: Reconhecimento de produtos em prateleiras, análise do comportamento de clientes em lojas.
O processo de Visão Computacional geralmente envolve as seguintes etapas:
- Aquisição de Imagem: Obtenção da imagem através de uma câmera, sensor ou arquivo.
- Pré-Processamento: Melhoria da qualidade da imagem (remoção de ruídos, ajustes de brilho e contraste, etc.).
- Extração de Características: Identificação de padrões e elementos importantes na imagem (bordas, cantos, texturas, etc.).
- Classificação: Atribuição de um rótulo ou categoria à imagem com base nas características extraídas (ex: “gato”, “cachorro”, “carro”, “pessoa”).
A escolha de Java para tarefas de Visão Computacional pode surpreender alguns, mas a verdade é que Java oferece um ecossistema rico em bibliotecas e ferramentas para Computer Vision, além de ser uma linguagem robusta, escalável e com excelente performance. Com as bibliotecas certas, podemos construir aplicações de Visão Computacional poderosas e eficientes em Java.
Preparando o ambiente: Configurando as ferramentas essenciais
Para começar a desvendar os segredos da Visão Computacional em Java, precisamos configurar nosso ambiente de desenvolvimento com as ferramentas e bibliotecas essenciais. Neste post, utilizaremos principalmente a biblioteca Deeplearning4j (DL4J), um framework de deep learning para Java que oferece um conjunto abrangente de recursos para construir, treinar e implementar modelos de redes neurais.
Além do DL4J, você pode considerar o uso da biblioteca OpenCV para tarefas de processamento de imagem mais básicas, como carregamento, redimensionamento e conversão de formatos. No entanto, para este exemplo focado em deep learning, o DL4J será suficiente.
Aqui estão os passos para configurar seu ambiente:
- Crie um Projeto Maven/Gradle: Utilize o Maven ou o Gradle para gerenciar as dependências do seu projeto. Neste post, utilizaremos o Maven.
- Adicione as Dependências do DL4J: Adicione as seguintes dependências ao arquivo pom.xml do seu projeto Maven:
<dependencies>
<!-- Outras dependências do projeto -->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native-platform</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.17</version>
</dependency>
</dependencies>Se você tiver uma GPU Nvidia, pode instalar o cuda-toolkit e o cudnn para obter processamento mais rápido das fases de treinamento e teste da rede neural. Neste caso, utilize as dependências abaixo, que são compatíveis com o CUDA 11.6:
<dependencies>
<!-- Outras dependências anteriores -->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<dependency>
<groupId>org.bytedeco</groupId>
<artifactId>cuda-platform</artifactId>
<version>12.3-8.9-1.5.10</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-cuda-11.6</artifactId>
<version>1.0.0-M2.1</version>
</dependency>
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-cuda-11.6</artifactId>
<version>1.0.0-M2.1</version>
<classifier>linux-x86_64-cudnn</classifier>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.17</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>2.0.17</version>
</dependency>
</dependencies>Após adicionar as dependências, salve o arquivo pom.xml e o Maven irá baixar e instalar as bibliotecas automaticamente, dependendo da sua IDE.
Com o ambiente configurado, estamos prontos para começar a trabalhar com Visão Computacional em Java! No próximo tópico, vamos aprender a obter e organizar um dataset de imagens de gatos e cachorros.
Obtendo e organizando o dataset: Gatos e cachorros ao seu comando
Para treinar nosso classificador de imagens de gatos e cachorros, precisamos de um dataset de imagens rotuladas. Existem diversas opções para obter um dataset adequado:
- Kaggle: O Kaggle é uma plataforma popular para competições de data science que também oferece diversos datasets públicos. Você pode encontrar datasets de gatos e cachorros no Kaggle, como o “Dogs vs. Cats“.
- Datasets Públicos: Existem outros datasets públicos de imagens de animais disponíveis online. Uma simples pesquisa no Google por “cat dog image dataset” pode te levar a diversas opções.
- Web Scraping: Se você não encontrar um dataset pronto, você pode coletar imagens da web utilizando técnicas de web scraping. No entanto, essa opção exige mais trabalho e cuidado para garantir a qualidade e a legalidade das imagens.
Para este post, vamos assumir que você já baixou um dataset de imagens de gatos e cachorros e o organizou em uma estrutura de diretórios semelhante a esta:
data/
train/
cats/
cat.0.jpg
cat.1.jpg
...
dogs/
dog.0.jpg
dog.1.jpg
...
validation/
cats/
cat.1000.jpg
cat.1001.jpg
...
dogs/
dog.1000.jpg
dog.1001.jpg
...
test/
cats/
cat.2000.jpg
cat.2001.jpg
...
dogs/
dog.2000.jpg
dog.2001.jpg
...Explicando a estrutura de pastas
- data/: Diretório raiz do dataset.
- train/: Diretório contendo as imagens de treinamento.
- validation/: Diretório contendo as imagens de validação (utilizadas para ajustar os hiperparâmetros do modelo).
- test/: Diretório contendo as imagens de teste (utilizadas para avaliar a performance final do modelo).
- cats/: Diretório contendo as imagens de gatos.
- dogs/: Diretório contendo as imagens de cachorros.
É fundamental organizar seu dataset dessa forma para facilitar o carregamento e o pré-processamento das imagens. Ao separar os dados em conjuntos de treinamento, validação e teste, garantimos que o modelo seja avaliado de forma justa e que não haja overfitting (quando o modelo aprende os dados de treinamento de cor, mas não generaliza bem para dados novos).
Após organizar o dataset, coloque na pasta src/main/resources do projeto.
Agora estamos prontos para começar a carregar e pré-processar as imagens em Java. No próximo tópico, vamos aprender a transformar pixels em dados úteis para o nosso modelo de deep learning.
Carregando e pré-processando as imagens: De pixels a dados úteis
Agora que temos nosso dataset organizado, precisamos carregar as imagens em Java e prepará-las para alimentar nosso modelo de deep learning. Essa etapa de pré-processamento é crucial para garantir a qualidade do modelo e evitar problemas como convergência lenta e overfitting.
Neste post, utilizaremos as classes do DL4J para carregar, redimensionar e normalizar as imagens. Aqui está um exemplo de código Java que demonstra como realizar essas tarefas:
import java.io.File;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import java.util.Random;
import org.datavec.api.io.filters.BalancedPathFilter;
import org.datavec.api.io.labels.ParentPathLabelGenerator;
import org.datavec.api.split.FileSplit;
import org.datavec.api.split.InputSplit;
import org.datavec.image.loader.NativeImageLoader;
import org.datavec.image.recordreader.ImageRecordReader;
import org.datavec.image.transform.FlipImageTransform;
import org.datavec.image.transform.ImageTransform;
import org.datavec.image.transform.PipelineImageTransform;
import org.datavec.image.transform.ResizeImageTransform;
import org.datavec.image.transform.RotateImageTransform;
import org.datavec.image.transform.WarpImageTransform;
import org.deeplearning4j.datasets.datavec.RecordReaderDataSetIterator;
import org.nd4j.common.io.ClassPathResource;
import org.nd4j.common.primitives.Pair;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
import org.nd4j.linalg.dataset.api.preprocessor.DataNormalization;
import org.nd4j.linalg.dataset.api.preprocessor.ImagePreProcessingScaler;
public class ImageLoader {
private static final int HEIGHT = 64;
private static final int WIDTH = 64;
private static final int CHANNELS = 3;
private static final Random RNG = new Random(123);
public static DataSetIterator getDataIterator(File rootDir, int batchSize, boolean isTrain, boolean includeTransforms) throws IOException {
// Define a raiz do diretório com as imagens
FileSplit filesInDir = new FileSplit(rootDir, NativeImageLoader.ALLOWED_FORMATS, RNG);
// Define o mecanismo para gerar os labels das imagens
ParentPathLabelGenerator labelMaker = new ParentPathLabelGenerator();
// Divisão dos dados em treinamento e teste
BalancedPathFilter pathFilter = new BalancedPathFilter(RNG, NativeImageLoader.ALLOWED_FORMATS, labelMaker);
InputSplit[] filesInDirSplit = filesInDir.sample(pathFilter, 0.8, 0.2);
InputSplit data = isTrain ? filesInDirSplit[0] : filesInDirSplit[1];
// Definindo transforms para as imagens
ImageTransform transform = null;
if (includeTransforms) {
List<Pair<ImageTransform, Double>> pipeline = new LinkedList<>();
pipeline.add(new Pair<>(new FlipImageTransform(), 0.5));
pipeline.add(new Pair<>(new RotateImageTransform(1), 0.5));
pipeline.add(new Pair<>(new WarpImageTransform(0.5f), 0.5));
pipeline.add(new Pair<>(new ResizeImageTransform(64, 64), 1.0));
transform = new PipelineImageTransform(pipeline, true);
}
// DataSetIterator
ImageRecordReader recordReader = new ImageRecordReader(HEIGHT, WIDTH, CHANNELS, labelMaker);
recordReader.initialize(data, transform);
DataSetIterator iterator = new RecordReaderDataSetIterator(recordReader, batchSize, 1, recordReader.numLabels());
// Normalização dos dados
DataNormalization scaler = new ImagePreProcessingScaler(0, 1);
iterator.setPreProcessor(scaler);
return iterator;
}
public static void main(String[] args) throws IOException {
File rootDir = new ClassPathResource("data").getFile();
int batchSize = 16;
DataSetIterator trainIter = getDataIterator(rootDir, batchSize, true, true);
DataSetIterator testIter = getDataIterator(rootDir, batchSize, false, true);
System.out.println("Exemplo de uso com o iterador de treinamento:");
System.out.println("Train features shape: " + trainIter.next().getFeatures().shapeInfoToString());
System.out.println("Test features shape: " + testIter.next().getFeatures().shapeInfoToString());
}
}- Definindo o tamanho das imagens: As variáveis height e width definem a altura e largura das imagens que vamos usar. Isso garante que todas as imagens tenham o mesmo tamanho, facilitando o processamento pelo modelo.
- getDataIterator(): Este método é responsável por carregar as imagens do disco, redimensioná-las e normalizar os valores dos pixels.
- FileSplit: Essa classe recebe um diretório raiz e retorna todos os arquivos dentro desse diretório, além de permitir filtrar por tipo de arquivo
- ParentPathLabelGenerator: Essa classe cria um label com base no nome do diretório pai. Caso a imagem esteja em train/cats/cat0.png, o label gerado seria cats.
- ImageTransform: Interface que representa uma transformação de imagem.
- PipelineImageTransform: Essa classe permite realizar um encadeamento de transforms.
- FlipImageTransform: Implementação de um transform que realiza o flip horizontal da imagem, permitindo aumentar a quantidade de dados e evitar o overfitting.
- ResizeImageTransform: Implementação de um transform que redimensiona a imagem.
- NativeImageLoader: Essa classe carrega as imagens do disco e as transforma em um array numérico, facilitando o uso do deeplearning4j.
- ImageRecordReader: Implementação do org.datavec.api.records.reader.RecordReader para leitura de imagens
- RecordReaderDataSetIterator : Essa classe itera sobre as imagens, permitindo carregar as imagens em batches.
Ao executar este código, você verá uma saída semelhante a:
Exemplo de uso com o iterador de treinamento:
Train features shape: Rank: 4, DataType: FLOAT, Offset: 0, Order: c, Shape: [16,3,64,64], Stride: [12288,4096,64,1]
Test features shape: Rank: 4, DataType: FLOAT, Offset: 0, Order: c, Shape: [16,3,64,64], Stride: [12288,4096,64,1]Observe que o formato dos Features agora é [16, 3, 64, 64]. Isso significa que temos um batch de 16 imagens, cada uma com 3 canais de cor (RGB), altura de 64 pixels e largura de 64 pixels.
Com as imagens carregadas e pré-processadas, estamos prontos para construir nosso modelo de deep learning! No próximo tópico, vamos aprender a criar uma Rede Neural Convolucional (CNN) utilizando Deeplearning4j.
Construindo o modelo de Deep Learning: A mágica das Redes Neurais
Chegou o momento de construir a espinha dorsal do nosso classificador de imagens: a Rede Neural Convolucional (CNN). As CNNs são uma classe de modelos de deep learning especialmente projetadas para processar dados com estrutura em grade, como imagens. Elas são capazes de aprender automaticamente as características mais relevantes das imagens, sem a necessidade de intervenção humana.
Uma CNN é composta por diversas camadas, cada uma com uma função específica:
- Camadas Convolucionais: Aplicam filtros convolucionais à imagem para extrair características como bordas, cantos e texturas. Cada filtro aprende a detectar um padrão específico na imagem.
- Camadas de Pooling: Reduzem a dimensionalidade da imagem, tornando o modelo mais eficiente e resistente a pequenas variações nas imagens.
- Função de Ativação: Aplicam uma função não linear a cada elemento da matriz resultante da convolução, dando ao modelo a capacidade de aprender padrões complexos. ReLu (Rectified Linear Unit) é uma das funções de ativação mais utilizadas.
- Camadas Totalmente Conectadas (Fully Connected): Combinam as características extraídas pelas camadas convolucionais para realizar a classificação final.
- Dropout: Desativa neurônios aleatoriamente durante o treinamento para evitar o overfitting.
Aqui está um exemplo de código Java que demonstra como construir uma CNN simples utilizando Deeplearning4j:
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.inputs.InputType;
import org.deeplearning4j.nn.conf.layers.*;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.learning.config.Nadam;
import org.nd4j.linalg.lossfunctions.LossFunctions;
public class CNNModel {
private static final int HEIGHT = 64;
private static final int WIDTH = 64;
private static final int CHANNELS = 3;
private static final int NUM_LABELS = 2; // Gato ou cachorro
private static final int SEED = 123;
public static MultiLayerNetwork buildModel() {
MultiLayerConfiguration configuration = new NeuralNetConfiguration.Builder()
.seed(SEED)
.weightInit(WeightInit.XAVIER)
.updater(new Nadam(0.001))
.l2(1e-4)
.list()
.layer(new ConvolutionLayer.Builder(5, 5)
.nIn(CHANNELS)
.stride(1, 1)
.nOut(32)
.activation(Activation.RELU)
.build())
.layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
.layer(new ConvolutionLayer.Builder(3, 3)
.stride(1, 1)
.nOut(64)
.activation(Activation.RELU)
.build())
.layer(new SubsamplingLayer.Builder(SubsamplingLayer.PoolingType.MAX)
.kernelSize(2, 2)
.stride(2, 2)
.build())
.layer(new DenseLayer.Builder().nOut(512).activation(Activation.RELU).build())
.layer(new OutputLayer.Builder(LossFunctions.LossFunction.MCXENT)
.nOut(NUM_LABELS)
.activation(Activation.SOFTMAX)
.build())
.setInputType(InputType.convolutional(HEIGHT, WIDTH, CHANNELS))
.build();
MultiLayerNetwork model = new MultiLayerNetwork(configuration);
model.init();
return model;
}
public static void main(String[] args) {
MultiLayerNetwork model = buildModel();
System.out.println("Modelo CNN construido:");
System.out.println(model.summary());
}
}- Definindo as Constantes: As variáveis height, width, channels e numLabels definem as dimensões das imagens de entrada, o número de canais de cores e o número de classes (gatos e cachorros), respectivamente.
- buildModel(): Este método é responsável por construir a arquitetura da CNN.
- NeuralNetConfiguration.Builder(): Classe do DL4J utilizada para definir a configuração da rede neural.
- ConvolutionLayer.Builder(): Cria a camada de Convolução
- kernelSize(5, 5): Tamanho do kernel (janela de convolução). Neste caso, 5×5 pixels.
- stride(1, 1): Define o deslocamento do kernel ao longo da imagem. Neste caso, o kernel se move 1 pixel por vez na horizontal e na vertical.
- nOut(32): Define o número de filtros (mapas de características) que a camada irá aprender. Neste caso, 32 filtros.
- activation(Activation.RELU): Define a função de ativação utilizada na camada. Neste caso, a função ReLU (Rectified Linear Unit).
- SubsamplingLayer.Builder(): Cria a camada de Pooling
- kernelSize(2, 2): Define o tamanho da janela de pooling. Neste caso, 2×2 pixels.
- stride(2, 2): Define o deslocamento da janela de pooling ao longo da imagem. Neste caso, a janela se move 2 pixels por vez na horizontal e na vertical.
- PoolingType.MAX: Utiliza o valor máximo dentro da janela como o valor de saída.
- DenseLayer.Builder(): Cria a camada fully connected.
- nOut(512): Número de neurônios na camada.
- activation(Activation.RELU): Define a função de ativação utilizada na camada.
- OutputLayer.Builder(): Cria a camada de saída.
- nOut(numLabels): Define o número de classes que a rede neural vai classificar
- LossFunctions.LossFunction.MCXENT: Função de loss utilizada
- Activation.SOFTMAX: A função de ativação softmax garante que as saídas da rede neural possam ser interpretadas como probabilidades.
- setInputType(InputType.convolutional(height, width, channels)): Define o tipo de entrada da rede neural como sendo uma imagem com as dimensões especificadas.
- MultiLayerNetwork: Classe do DL4J responsável por inicializar o modelo.
Ao executar este código, você verá a arquitetura do modelo CNN sendo impressa no console.
Modelo CNN construido:
============================================================================
LayerName (LayerType) nIn,nOut TotalParams ParamsShape
============================================================================
layer0 (ConvolutionLayer) 3,32 2.432 b:{32}, W:{32,3,5,5}
layer1 (SubsamplingLayer) -,- 0 -
layer2 (ConvolutionLayer) 32,64 18.496 b:{64}, W:{64,32,3,3}
layer3 (SubsamplingLayer) -,- 0 -
layer4 (DenseLayer) 12544,512 6.423.040 W:{12544,512}, b:{512}
layer5 (OutputLayer) 512,2 1.026 W:{512,2}, b:{2}
----------------------------------------------------------------------------
Total Parameters: 6.444.994
Trainable Parameters: 6.444.994
Frozen Parameters: 0
============================================================================Com o modelo construído, estamos prontos para treiná-lo com os dados de treinamento. No próximo tópico, vamos aprender a “ensinar” a máquina a reconhecer gatos e cachorros.
Treinando o modelo: Ensinando a máquina a ver
Com a CNN construída, o próximo passo é treinar o modelo. O treinamento consiste em alimentar o modelo com os dados de treinamento (as imagens de gatos e cachorros rotuladas) e ajustar os pesos das conexões entre os neurônios para que o modelo aprenda a classificar as imagens corretamente.
Durante o treinamento, o modelo passa repetidamente pelos dados de treinamento (cada passagem é chamada de epoch) e ajusta seus pesos para minimizar o erro entre as previsões e os rótulos reais. A quantidade de imagens processadas em cada iteração é controlada pelo batch size. A taxa de aprendizado (learning rate) controla a magnitude dos ajustes nos pesos.
Aqui está um exemplo de código Java que demonstra como treinar a CNN utilizando Deeplearning4j:
import java.io.File;
import java.io.IOException;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.util.ModelSerializer;
import org.nd4j.common.io.ClassPathResource;
import org.nd4j.linalg.dataset.api.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
public class TrainModel {
public static void main(String[] args) throws IOException {
int batchSize = 64;
int numEpochs = 10;
String modelPath = "modelo_gatos_cachorros.zip";
File rootDir = new ClassPathResource("data").getFile();
DataSetIterator trainIter = ImageLoader.getDataIterator(rootDir, batchSize, true, true);
MultiLayerNetwork model = CNNModel.buildModel();
System.out.println("Iniciando o treinamento...");
for (int i = 0; i < numEpochs; i++) {
while (trainIter.hasNext()) {
try {
DataSet data = trainIter.next();
model.fit(data);
} catch(Exception e) {}
}
trainIter.reset();
System.out.println("Epoch " + i + " completada");
}
System.out.println("Treinamento finalizado!");
System.out.println("Salvando o modelo...");
File locationToSave = new File(modelPath);
boolean saveUpdater = true;
ModelSerializer.writeModel(model, locationToSave, saveUpdater);
System.out.println("Modelo salvo em: " + locationToSave.getAbsolutePath());
}
}- Definindo as Configurações: As variáveis batchSize e numEpochs definem o tamanho do batch e o número de épocas, respectivamente. Ajuste esses valores para otimizar o treinamento do seu modelo.
- Carrega o Dataset: O código carrega o dataset utilizando o método ImageLoader.getDataIterator() que definimos no tópico anterior.
- Constrói o Modelo: O código constrói o modelo CNN utilizando o método CNNModel.buildModel() que definimos no tópico anterior.
- Loop de Treinamento: O código itera sobre as épocas e os batches do dataset de treinamento.
- model.fit(data): Este método alimenta o modelo com um batch de dados e ajusta os pesos das conexões para minimizar o erro.
- trainIter.reset(): Este método reseta o iterador do dataset para que ele volte ao início no início de cada época.
- Ao final, salvamos o modelo treinado no arquivo
modelo_gatos_cachorros.zip, para que não seja necessário passar por todo o processo de treinamento sempre que quiser utilizar a ferramenta.
Ao executar este código, você verá o progresso do treinamento sendo impresso no console. A cada época, o modelo estará aprendendo a classificar as imagens com maior precisão.
Lembrando que você pode ajustar os valores das variáveis batchSize e numEpochs para melhorar a taxa de aprendizado. Quanto mais épocas a rede passar aprendendo, melhor será o resultado, mas também levará mais tempo para concluir o treinamento. Tome cuidado para não treinar demais a rede, pois você pode passar por um problema de overfitting, onde uma rede aprende bem demais com os dados de treino, mas não consegue prever dados reais.
Após o treinamento, o modelo estará pronto para ser avaliado e utilizado para classificar novas imagens. No próximo tópico, vamos aprender carregar o modelo treinado a partir do arquivo modelo_gatos_cachorros.zip.
Carregando o modelo treinado
Depois de treinar o modelo e salvá-lo em um arquivo, podemos carregá-lo e reutilizá-lo em outras aplicações sem precisar passar pelo processo de treinamento novamente.
Aqui está um exemplo de código Java que demonstra como carregar o modelo treinado utilizando Deeplearning4j:
import java.io.File;
import java.io.IOException;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.util.ModelSerializer; // Importe a classe ModelSerializer
public class LoadModel {
public static MultiLayerNetwork loadModel(String modelPath) throws IOException {
File locationToLoad = new File(modelPath);
MultiLayerNetwork restoredNetwork = ModelSerializer.restoreMultiLayerNetwork(locationToLoad);
return restoredNetwork;
}
public static void main(String[] args) throws IOException {
// O mesmo caminho usado para salvar o modelo
String modelPath = "modelo_gatos_cachorros.zip";
MultiLayerNetwork model = loadModel(modelPath);
System.out.println("Modelo carregado com sucesso!");
// Imprime a arquitetura do modelo para verificar
System.out.println(model.summary());
}
}- loadModel(String modelPath): Este método recebe o caminho do arquivo onde o modelo foi salvo e utiliza o método ModelSerializer.restoreMultiLayerNetwork() para carregar o modelo na memória.
- main(): No método main(), chamamos o método loadModel() para carregar o modelo e imprimimos um resumo da arquitetura do modelo para verificar se ele foi carregado corretamente.
Com este código, você pode facilmente carregar o modelo treinado e utilizá-lo para classificar novas imagens.
No próximo tópico, vamos aprender a avaliar a performance do modelo e medir a precisão da sua “visão”.
Medindo a precisão da visão
Após treinar o modelo (ou carregá-lo de um arquivo salvo), precisamos avaliar sua performance para verificar o quão bem ele consegue classificar imagens de gatos e cachorros. Para isso, utilizaremos o conjunto de testes que separamos durante a etapa de organização do dataset.
Para avaliar o modelo, vamos calcular as seguintes métricas:
- Precisão (Precision): A proporção de imagens classificadas como “gato” que realmente são gatos, e a proporção de imagens classificadas como “cachorro” que realmente são cachorros.
- Recall (Revocação): A proporção de todas as imagens de gatos que foram corretamente classificadas como “gato”, e a proporção de todas as imagens de cachorros que foram corretamente classificadas como “cachorro”.
- F1-Score: Uma média harmônica entre precisão e recall, que fornece uma medida geral da performance do modelo.
Além das métricas, também construiremos uma matriz de confusão para visualizar os erros do modelo. A matriz de confusão mostra quantos gatos foram classificados como gatos (Verdadeiros Positivos), quantos gatos foram classificados como cachorros (Falsos Negativos), quantos cachorros foram classificados como cachorros (Verdadeiros Negativos) e quantos cachorros foram classificados como gatos (Falsos Positivos).
Aqui está um exemplo de código Java que demonstra como avaliar o modelo utilizando Deeplearning4j, com a lógica de carregamento do modelo já existente:
import java.io.File;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.common.io.ClassPathResource;
import org.nd4j.evaluation.classification.Evaluation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.dataset.api.DataSet;
import org.nd4j.linalg.dataset.api.iterator.DataSetIterator;
public class EvaluateModel {
public static void main(String[] args) throws IOException {
// Defina as configurações
int batchSize = 32;
String modelPath = "modelo_gatos_cachorros.zip"; // O caminho para o modelo salvo
File modelFile = new File(modelPath);
// Carrega o dataset de teste
File rootDir = new ClassPathResource("data").getFile();
DataSetIterator testIter = ImageLoader.getDataIterator(rootDir, batchSize, true, false); // Carrega o dataset de teste sem transforms
// Carrega o modelo (se existir) ou treina um novo
MultiLayerNetwork model;
if (modelFile.exists()) {
System.out.println("Carregando modelo existente...");
model = LoadModel.loadModel(modelPath); // Utiliza a classe LoadModel que você criou
} else {
System.out.println("Modelo não encontrado. Iniciando o treinamento...");
TrainModel.main(null); // Utiliza a classe TrainModel que você criou para treinar o modelo
model = LoadModel.loadModel(modelPath); // Carrega o modelo treinado
}
// Avalia o modelo
System.out.println("Iniciando a avaliação do modelo...");
List<String> labels = new ArrayList<>();
labels.add("Cat");
labels.add("Dog");
Evaluation evaluation = new Evaluation();
while (testIter.hasNext()) {
try {
DataSet testData = testIter.next();
INDArray features = testData.getFeatures();
INDArray labelsArray = testData.getLabels();
INDArray predictions = model.output(features);
evaluation.eval(labelsArray, predictions);
} catch(Exception e) {}
}
System.out.println(evaluation.stats()); // Imprime as estatísticas da avaliação
}
}- Definindo as Configurações: As variáveis batchSize e modelPath definem o tamanho do batch e o caminho para o modelo salvo, respectivamente.
- Carrega o Dataset: O código carrega o dataset de teste utilizando o método ImageLoader.getDataIterator(). Importante: Certifique-se de carregar o dataset de teste sem transformações (o parâmetro includeTransforms deve ser false).
- Carrega o Modelo (se existir) ou Treina um Novo: O código verifica se o arquivo do modelo existe. Se existir, ele carrega o modelo utilizando a classe LoadModel que você criou. Caso contrário, ele chama a classe TrainModel para treinar um novo modelo e, em seguida, carrega o modelo treinado.
- Evaluation: Classe do DL4J responsável por calcular as métricas de avaliação e construir a matriz de confusão.
- Iteração sobre o Dataset de Teste: O código itera sobre os batches do dataset de teste.
- model.output(features): Este método alimenta o modelo com um batch de imagens e retorna as predições do modelo.
- evaluation.eval(labelsArray, predictions): Este método compara as predições do modelo com os rótulos reais e atualiza as estatísticas da avaliação.
- System.out.println(evaluation.stats()): Imprime as estatísticas da avaliação, incluindo precisão, recall, F1-score e a matriz de confusão.
Ao executar este código, você verá as estatísticas da avaliação e a matriz de confusão sendo impressas no console. Utilize essas informações para avaliar a performance do seu modelo e identificar possíveis áreas de melhoria.
Para o modelo deste exemplo, usei um batchSize de 32 e o numEpochs de 30, e o resultado do treinamento saiu desta forma:
========================Evaluation Metrics========================
# of classes: 2
Accuracy: 0,6989
Precision: 0,7854
Recall: 0,5475
F1 Score: 0,6452
Precision, recall & F1: reported for positive class (class 1 - "1") only
=========================Confusion Matrix=========================
0 1
-----------
1932 340 | 0 = 0
1028 1244 | 1 = 1
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================Pode-se notar que a precisão está próxima de 79%, que para fins didáticos, está ótimo.
Com a avaliação completa, você tem uma visão clara de quão bem seu modelo está “enxergando” gatos e cachorros. No próximo tópico, vamos aprender a testar o modelo com novas imagens e colocar a IA à prova!
Testando o modelo com novas imagens
Agora que temos um modelo treinado, e conhecemos a capacidade de previsão, podemos criar uma interface simples para fazer previsões com base em imagens da Web. Vamos criar um programa simples em que o usuário consiga inserir uma URL de uma imagem, e a rede faça a previsão com base no que aprendeu.
Atenção: Este código requer a permissão java.net.SocketPermission para acessar a internet. Para executá-lo, você precisará adicionar essa permissão ao seu arquivo java.policy ou executar o código com a opção -Djava.security.policy.
import java.awt.BorderLayout;
import java.awt.FlowLayout;
import java.awt.Graphics2D;
import java.awt.GridBagLayout;
import java.awt.Image;
import java.awt.event.ActionEvent;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.net.URL;
import javax.imageio.ImageIO;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JOptionPane;
import javax.swing.JPanel;
import javax.swing.JTextField;
import javax.swing.SwingConstants;
import javax.swing.SwingUtilities;
import javax.swing.UIManager;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.factory.Nd4j;
public class ImageClassifierApp extends JFrame {
private static final long serialVersionUID = -3801359864887032359L;
private JTextField urlTextField;
private JLabel imageLabel;
private JLabel resultLabel;
private MultiLayerNetwork model;
private static final int height = 64;
private static final int width = 64;
private static final int channels = 3;
public ImageClassifierApp() {
super("Image Classifier");
// Carrega o modelo treinado
try {
String modelPath = "modelo_gatos_cachorros.zip"; // O caminho para o modelo salvo
File modelFile = new File(modelPath);
if (!modelFile.exists()) {
System.out.println("Modelo não encontrado. Treinando...");
TrainModel.main(null); // Utilize a classe TrainModel que você criou para treinar o modelo
}
model = LoadModel.loadModel(modelPath); // Utilize a classe LoadModel que você criou para carregar o modelo
} catch (IOException e) {
JOptionPane.showMessageDialog(this, "Erro ao carregar o modelo: " + e.getMessage(), "Erro", JOptionPane.ERROR_MESSAGE);
System.exit(1);
}
// Cria os componentes da interface
urlTextField = new JTextField(30);
imageLabel = new JLabel();
resultLabel = new JLabel("Insira a URL da imagem e clique em Classificar", SwingConstants.CENTER);
JButton classifyButton = new JButton("Classificar");
// Painel superior para URL e botão
JPanel topPanel = new JPanel(new FlowLayout(FlowLayout.CENTER));
topPanel.add(new JLabel("URL da Imagem:"));
topPanel.add(urlTextField);
topPanel.add(classifyButton);
// Painel central para a imagem
JPanel centerPanel = new JPanel(new GridBagLayout()); // Use GridBagLayout para centralizar
centerPanel.add(imageLabel);
// Define o layout da interface
setLayout(new BorderLayout());
add(topPanel, BorderLayout.NORTH);
add(centerPanel, BorderLayout.CENTER);
add(resultLabel, BorderLayout.SOUTH);
// Adiciona o listener para o botão de classificação
classifyButton.addActionListener(this::classifyImage);
// Configura a janela
setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
setSize(800, 600);
setLocationRelativeTo(null);
setVisible(true);
}
private void classifyImage(ActionEvent e) {
try {
// Obtém a URL da imagem
String imageUrl = urlTextField.getText();
if (imageUrl == null || imageUrl.trim().isEmpty()) {
JOptionPane.showMessageDialog(this, "Por favor, insira a URL da imagem.", "Aviso", JOptionPane.WARNING_MESSAGE);
return;
}
// Carrega a imagem da URL
BufferedImage img = ImageIO.read(new URL(imageUrl));
// Pré-processa a imagem
BufferedImage resizedImage = resizeImage(img, width, height);
INDArray imageArray = loadImage(resizedImage);
// Realiza a classificação
INDArray output = model.output(imageArray);
int predictedClass = Nd4j.argMax(output, 1).getInt(0);
String className = (predictedClass == 0) ? "Cat" : "Dog";
// Atualiza a interface
ImageIcon icon = new ImageIcon(img.getScaledInstance(200, 200, Image.SCALE_SMOOTH));
imageLabel.setIcon(icon);
resultLabel.setText("Classificação: " + className);
} catch (IOException ex) {
JOptionPane.showMessageDialog(this, "Erro ao carregar a imagem: " + ex.getMessage(), "Erro", JOptionPane.ERROR_MESSAGE);
} catch (Exception ex) {
JOptionPane.showMessageDialog(this, "Erro ao classificar a imagem: " + ex.getMessage(), "Erro", JOptionPane.ERROR_MESSAGE);
}
}
private BufferedImage resizeImage(BufferedImage originalImage, int targetWidth, int targetHeight) {
BufferedImage resizedImage = new BufferedImage(targetWidth, targetHeight, BufferedImage.TYPE_INT_RGB);
Graphics2D graphics2D = resizedImage.createGraphics();
graphics2D.drawImage(originalImage, 0, 0, targetWidth, targetHeight, null);
graphics2D.dispose();
return resizedImage;
}
private INDArray loadImage(BufferedImage bufferedImage) throws IOException {
int[] shape = {1, channels, height, width};
INDArray imageArray = Nd4j.zeros(shape);
// Get pixel data from image and store into a line buffer
int[] pixelData = new int[height * width];
bufferedImage.getRGB(0, 0, width, height, pixelData, 0, width);
double[] normalizedPixelValues = new double[height * width * channels];
//Iterate over the entire buffer and normalise all values
for (int i = 0; i < pixelData.length; i++) {
int blue = pixelData[i] & 0xFF;
int green = (pixelData[i] >> 8) & 0xFF;
int red = (pixelData[i] >> 16) & 0xFF;
normalizedPixelValues[i * 3] = (double) red / 255;
normalizedPixelValues[i * 3 + 1] = (double) green / 255;
normalizedPixelValues[i * 3 + 2] = (double) blue / 255;
}
imageArray.assign(Nd4j.create(normalizedPixelValues, shape));
return imageArray;
}
public static void main(String[] args) {
// Configura o Look and Feel da interface
try {
UIManager.setLookAndFeel("javax.swing.plaf.metal.MetalLookAndFeel");
} catch (Exception e) {
e.printStackTrace();
}
SwingUtilities.invokeLater(() -> new ImageClassifierApp());
}
}- ImageClassifierApp: Classe principal da aplicação, que estende JFrame para criar a janela da interface gráfica.
- MultiLayerNetwork model: Variável para armazenar o modelo treinado.
- ImageClassifierApp(): Construtor da classe, responsável por carregar o modelo, criar os componentes da interface e definir o layout.
- Carregamento do Modelo: No construtor, o código carrega o modelo treinado utilizando a classe LoadModel.
- Componentes da Interface: O código cria os componentes da interface:
- urlTextField: Campo de texto para o usuário inserir a URL da imagem.
- imageLabel: Label para exibir a imagem carregada.
- resultLabel: Label para exibir o resultado da classificação.
- classifyButton: Botão para iniciar a classificação.
- Layout da Interface: O código utiliza um FlowLayout para organizar os componentes na janela.
- classifyImage(ActionEvent e): Este método é chamado quando o botão “Classificar” é clicado. Ele carrega a imagem da URL fornecida pelo usuário, pré-processa a imagem, realiza a classificação utilizando o modelo e exibe o resultado na interface.
- Carrega a imagem da URL
- Redimensiona a imagem
- Normaliza os pixels
- Realiza a classificação com o modelo
- Atualiza a interface com a imagem e o resultado da classificação
- resizeImage(BufferedImage originalImage, int targetWidth, int targetHeight): Redimensiona a imagem
- loadImage(BufferedImage bufferedImage): Converte a imagem para um array INDArray do ND4J
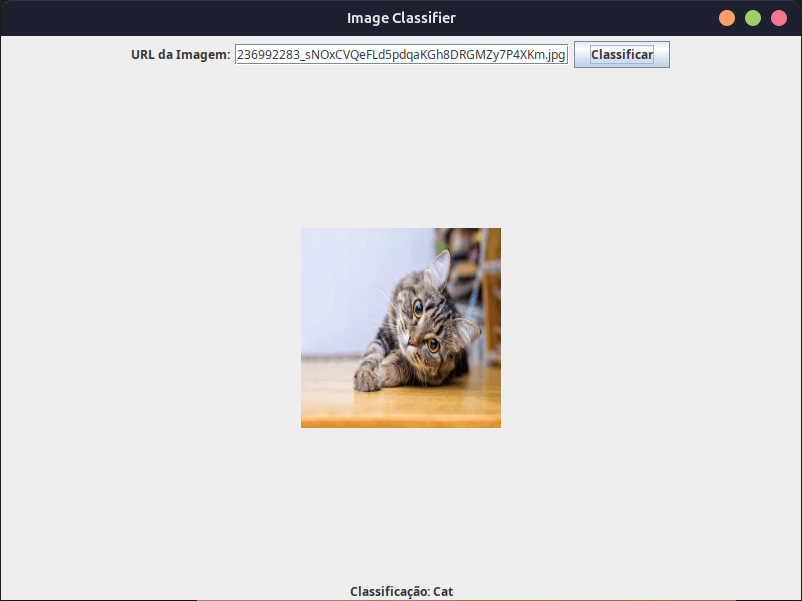
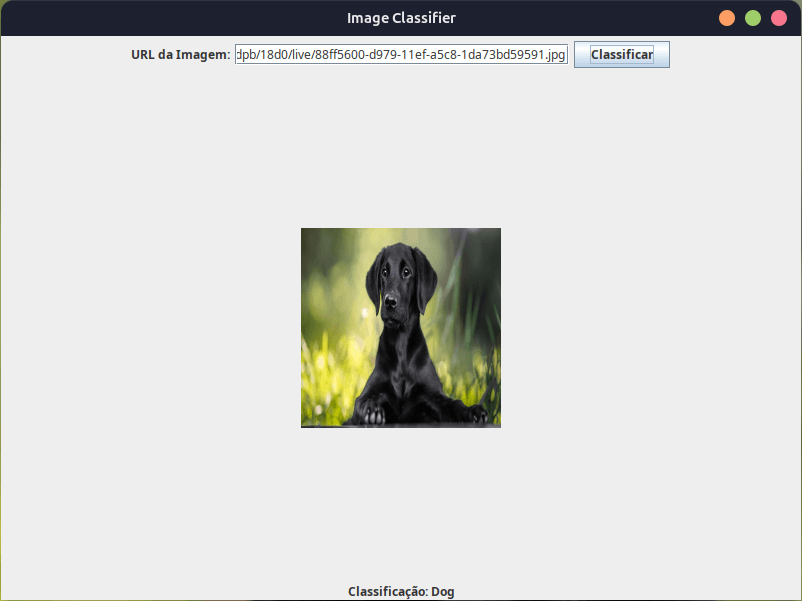
Executando o Código:
- Compile e execute o código Java.
- Uma janela será aberta com um campo de texto, um botão e dois labels.
- Insira a URL de uma imagem de gato ou cachorro no campo de texto e clique no botão “Classificar”.
- A imagem será exibida no label e o resultado da classificação (gato ou cachorro) será mostrado no outro label.
Indo Além: O futuro da visão computacional em Java
Construímos um classificador de imagens funcional, aprendemos os conceitos básicos de Redes Neurais Convolucionais e exploramos as possibilidades da linguagem Java nesse campo fascinante. Mas a jornada não termina aqui! O mundo da Visão Computacional está em constante evolução, e há muito mais para descobrir.
Aqui estão algumas áreas que você pode explorar para aprofundar seus conhecimentos e construir aplicações ainda mais poderosas:
- Detecção de Objetos: Em vez de apenas classificar a imagem como “gato” ou “cachorro”, podemos identificar e localizar múltiplos objetos na mesma imagem. Algoritmos como YOLO (You Only Look Once) e SSD (Single Shot MultiBox Detector) permitem detectar objetos em tempo real com alta precisão.
- Segmentação de Imagens: Em vez de apenas identificar os objetos, podemos segmentar a imagem em regiões que correspondem a diferentes objetos ou partes de objetos. Essa técnica é útil em aplicações como diagnóstico médico e carros autônomos.
- Reconhecimento Facial: Identificar e autenticar pessoas com base em suas características faciais. Essa tecnologia é utilizada em sistemas de segurança, redes sociais e aplicações de entretenimento.
- Visão Computacional 3D: Reconstruir modelos 3D do mundo a partir de imagens e vídeos. Essa área é fundamental para robótica, realidade aumentada e modelagem de cidades.
- Deep Learning para Vídeos: Analisar vídeos para identificar ações, eventos e padrões. Essa tecnologia é utilizada em sistemas de vigilância, análise de esportes e entretenimento.
Para se manter atualizado sobre as últimas tendências e avanços da Visão Computacional, recomendo que você acompanhe:
- Artigos Científicos: Leia artigos publicados em conferências como CVPR, ICCV e ECCV.
- Blogs e Tutoriais: Siga blogs e tutoriais especializados em Visão Computacional e Deep Learning.
- Repositórios do GitHub: Explore projetos de código aberto relacionados à Visão Computacional.
- Comunidades Online: Participe de fóruns e grupos de discussão sobre Visão Computacional.
O futuro da Visão Computacional em Java é brilhante. Com o poder das bibliotecas de deep learning e a versatilidade da linguagem Java, você pode construir aplicações inovadoras que transformam a maneira como interagimos com o mundo.
Conclusão
Parabéns! Você chegou ao fim desta emocionante jornada pelo mundo da Visão Computacional em Java! Percorremos um longo caminho, desde a compreensão dos conceitos básicos até a construção de um classificador de imagens funcional e a exploração de técnicas avançadas.
Aprendemos a:
- Preparar o ambiente de desenvolvimento com as bibliotecas essenciais.
- Obter e organizar um dataset de imagens.
- Carregar, pré-processar e aumentar as imagens.
- Construir e treinar uma Rede Neural Convolucional (CNN) com Deeplearning4j.
- Avaliar a performance do modelo utilizando métricas como precisão, recall e F1-score.
- Construir uma interface gráfica para testar o modelo com novas imagens da web.
Com as habilidades que você adquiriu neste post, você está pronto para explorar um universo de possibilidades e construir aplicações inovadoras em diversas áreas, como medicina, indústria, segurança, automobilística, agricultura e muito mais.
A Visão Computacional em Java é um campo em constante crescimento, e as oportunidades são vastas. Continue praticando, experimentando e explorando as novas tecnologias e tendências. O futuro da Visão Computacional está em suas mãos!
Se você gostou deste post, não se esqueça de compartilhá-lo com seus amigos e colegas que também se interessam por Inteligência Artificial e Visão Computacional. E deixe um comentário abaixo com suas dúvidas, sugestões e ideias. Queremos saber o que você achou desta jornada e como pretende aplicar o conhecimento que adquiriu!
Olá, mostre um exemplo para o uso de IA no sistema financeiro.