

Nos posts anteriores, exploramos Regressão Logística para classificar emojis e Regressão Linear para prever preços de imóveis. Agora, prepare-se para dominar uma técnica fundamental do Machine Learning não supervisionado: o KMeans! Se você quer descobrir padrões ocultos em seus dados, segmentar clientes ou organizar informações de forma inteligente, o KMeans é sua arma Jedi! Prepare-se para aprender como implementar o KMeans em Java.
Neste post, utilizaremos um exemplo prático de segmentação de clientes para mostrar como você pode aplicar o KMeans para revelar insights valiosos nos seus próprios projetos. Prepare-se para mergulhar no mundo do agrupamento de dados com Java e desvendar padrões que estavam ocultos até agora! 🚀
KMeans: Desvendando o algoritmo de agrupamento 🤓
Diferente dos algoritmos que vimos antes (Regressão Logística e Regressão Linear), o KMeans é um algoritmo de clustering (agrupamento). Isso significa que ele se enquadra no aprendizado não supervisionado. Em vez de prever um rótulo ou um valor, o KMeans busca agrupar dados similares em clusters (aglomerados) com base em suas características.
Pense da seguinte forma: Você tem um conjunto de pontos de dados (digamos, clientes com suas características de compra) e quer organizá-los em grupos “naturais” onde os pontos dentro de cada grupo sejam mais semelhantes entre si do que com pontos de outros grupos. O KMeans faz exatamente isso!
Como funciona o algoritmo KMeans?
O KMeans segue um processo iterativo para agrupar os dados. As etapas principais são:
- Inicialização dos Centróides: Primeiro, você precisa definir quantos clusters deseja formar (k é o número de clusters). O KMeans começa inicializando k pontos aleatórios como centróides iniciais (o “centro” de cada cluster).
- Atribuição aos Clusters: Em cada iteração, o algoritmo percorre todos os pontos de dados e atribui cada ponto ao cluster cujo centróide está mais próximo (geralmente usando a distância Euclidiana como medida de proximidade).
- Recálculo dos Centróides: Após atribuir todos os pontos a clusters, o KMeans recalcula a posição de cada centróide. O novo centróide de cada cluster se torna a média de todos os pontos que foram atribuídos a esse cluster na iteração atual.
- Iteração e Convergência: As etapas 2 e 3 (atribuição e recálculo) são repetidas iterativamente. A cada iteração, os centróides tendem a se mover e os clusters se ajustam. O algoritmo para de iterar quando os centróides praticamente não se movem mais (atinge a convergência), ou quando um número máximo de iterações é atingido.
Em resumo, o KMeans é um algoritmo iterativo que busca encontrar a melhor forma de particionar um conjunto de dados em k clusters, minimizando a distância intra-cluster (pontos dentro do mesmo cluster próximos entre si) e maximizando a distância inter-cluster (clusters bem separados uns dos outros).
Aplicações práticas do KMeans
O KMeans é incrivelmente versátil e útil em diversas áreas, incluindo:
- Segmentação de Clientes: Agrupar clientes com base em comportamentos de compra, dados demográficos, etc., para personalizar marketing, ofertas e estratégias de atendimento. (Nosso exemplo prático neste post!).
- Segmentação de Imagens: Agrupar pixels semelhantes em imagens para compressão, edição ou análise de imagens.
- Clustering de Documentos: Agrupar documentos de texto semelhantes por tópico, tema ou categoria, para organização, recomendação ou busca.
- Detecção de Anomalias: Identificar pontos de dados que não se encaixam em nenhum cluster bem definido, o que pode indicar anomalias, fraudes ou outliers.
Vamos agora implementar o algoritmo KMeans em Java e aplicá-lo à segmentação de clientes! 🧙♂️
Implementando o KMeans em Java 💻✍️
Vamos construir a classe KMeansClassifier em Java para implementar o algoritmo KMeans.
import org.nd4j.linalg.api.buffer.DataType;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.api.rng.Random;
import org.nd4j.linalg.cpu.nativecpu.rng.CpuNativeRandom;
import org.nd4j.linalg.factory.Nd4j;
public class KMeansClassifier {
private int k; // Número de clusters
private int maxIterations; // Máximo de iterações
public INDArray centroids; // Centróides dos clusters
public KMeansClassifier(int k, int maxIterations) {
this.k = k;
this.maxIterations = maxIterations;
}
public void initializeCentroids(INDArray data) {
int numSamples = data.rows();
int numFeatures = data.columns();
centroids = Nd4j.zeros(DataType.DOUBLE, k, numFeatures); // Inicializa matriz de centróides
try (Random random = new CpuNativeRandom()) {
for (int i = 0; i < k; i++) {
int randomIndex = random.nextInt(numSamples); // Escolhe um índice aleatório
centroids.putRow(i, data.getRow(randomIndex)); // Usa um ponto de dado aleatório como centróide inicial
}
} catch (Exception e) {
e.printStackTrace();
}
}
public int[] assignClusters(INDArray data, INDArray centroids) {
int numSamples = data.rows();
int[] clusterAssignments = new int[numSamples]; // Array para armazenar a qual cluster cada ponto foi atribuído
for (int i = 0; i < numSamples; i++) {
INDArray dataPoint = data.getRow(i);
int bestClusterIndex = -1;
double minDistance = Double.MAX_VALUE;
for (int j = 0; j < k; j++) {
INDArray centroid = centroids.getRow(j);
INDArray diff = dataPoint.sub(centroid); // Vetor diferença entre ponto e centróide
double distance = Nd4j.norm2(diff).getDouble(0); // Distância Euclidiana (norma L2)
if (distance < minDistance) {
minDistance = distance;
bestClusterIndex = j; // Índice do cluster com o centróide mais próximo
}
}
clusterAssignments[i] = bestClusterIndex; // Atribui o ponto ao cluster mais próximo
}
return clusterAssignments;
}
public INDArray updateCentroids(INDArray data, int[] clusterAssignments, int k) {
int numFeatures = data.columns();
INDArray newCentroids = Nd4j.zeros(DataType.DOUBLE, k, numFeatures); // Inicializa matriz para novos centróides
int[] clusterCounts = new int[k]; // Array para contar quantos pontos em cada cluster
for (int i = 0; i < data.rows(); i++) {
int clusterIndex = clusterAssignments[i];
// Soma os pontos de cada cluster nos respectivos centróides
newCentroids.putRow(clusterIndex, newCentroids.getRow(clusterIndex).addiRowVector(data.getRow(i)));
clusterCounts[clusterIndex]++; // Incrementa a contagem de pontos no cluster
}
// Calcula a média para cada cluster (novo centróide)
for (int i = 0; i < k; i++) {
if (clusterCounts[i] > 0) {
// Divide a soma pela contagem para obter a média
newCentroids.putRow(i, newCentroids.getRow(i).div(clusterCounts[i]));
}
}
return newCentroids; // Retorna os novos centróides recalculados
}
public void fit(INDArray data) {
initializeCentroids(data); // Inicializa os centróides
for (int iteration = 0; iteration < maxIterations; iteration++) {
int[] clusterAssignments = assignClusters(data, centroids); // Atribui pontos aos clusters
INDArray oldCentroids = centroids.dup(); // Copia os centróides antigos para verificar convergência
centroids = updateCentroids(data, clusterAssignments, k); // Recalcula os centróides
// Verifica convergência: se os centróides não mudaram significativamente, para de iterar
double centroidMovement = calculateCentroidMovement(oldCentroids, centroids);
System.out.println("Iteração " + iteration + ", Movimento dos Centróides: " + String.format("%.4f", centroidMovement));
if (centroidMovement < 1e-6) { // Critério de convergência: movimento dos centróides muito pequeno
System.out.println("KMeans Convergiu na Iteração " + iteration);
break; // Sai do loop de iterações se convergiu
}
}
}
private double calculateCentroidMovement(INDArray oldCentroids, INDArray newCentroids) {
INDArray diff = oldCentroids.sub(newCentroids);
return Nd4j.norm2(diff).getDouble(0); // Distância Euclidiana entre os centróides antigos e novos
}
public int[] predict(INDArray data) {
// Reutiliza a lógica de assignClusters, mas agora com os centróides já treinados
return assignClusters(data, centroids);
}
public double calculateSquaredErrors(INDArray data, INDArray centroids, int[] clusterAssignments) {
double totalSquaredError = 0;
for (int i = 0; i < data.rows(); i++) {
int clusterIndex = clusterAssignments[i];
INDArray centroid = centroids.getRow(clusterIndex);
INDArray diff = data.getRow(i).sub(centroid); // Vetor diferença entre ponto e seu centróide
double squaredError = Math.pow(Nd4j.norm2(diff).getDouble(0), 2); // Distância Euclidiana ao quadrado
totalSquaredError += squaredError; // Acumula o erro quadrático
}
return totalSquaredError; // Retorna a Soma Total dos Erros Quadrados (SSE)
}
}
Classe KMeansClassifier
- k: Número de clusters que desejamos encontrar (definido no construtor).
- maxIterations: Número máximo de iterações do algoritmo KMeans (para evitar loops infinitos caso a convergência seja lenta ou não ocorra).
- centroids: Um INDArray que irá armazenar as posições dos centróides de cada cluster.
Método initializeCentroids: Inicialização aleatória dos centróides
Este método inicializa os centróides escolhendo aleatoriamente k pontos de dados do dataset como centróides iniciais.
- centroids: Cria um INDArray para armazenar os centróides. Terá k linhas (um para cada centróide) e numFeatures colunas (o número de features de cada ponto de dado). Usamos DataType.DOUBLE para precisão numérica.
- Random random: Cria um gerador de números aleatórios.
- Loop for: Itera sobre o número de clusters (k).
- randomIndex: Gera um índice aleatório entre 0 e o número de pontos de dados – 1.
- centroids.putRow: Seleciona a linha (ponto de dado) correspondente ao randomIndex do dataset de entrada (data) e a utiliza como o i-ésimo centróide inicial, colocando-a na i-ésima linha da matriz centroids.
Método assignClusters: atribuição de pontos aos clusters
Este método atribui cada ponto de dado ao cluster cujo centróide está mais próximo.
- clusterAssignments: Cria um array de inteiros para armazenar a qual cluster cada ponto de dado será atribuído. O índice do array corresponde ao índice do ponto de dado no dataset original, e o valor em cada posição é o índice do cluster (0, 1, 2, … k-1).
- Loop externo for: Itera sobre cada ponto de dado no dataset de entrada (data).
- dataPoint: Obtém o i-ésimo ponto de dado.
- Loop interno for: Itera sobre cada centróide (cada cluster).
- centroid: Obtém o j-ésimo centróide.
- diff: Calcula o vetor diferença entre o ponto de dado e o centróide (subtração ponto a ponto).
- double distance: Calcula a distância Euclidiana (norma L2) do vetor diferença. Nd4j.norm2(diff) calcula a norma L2 do vetor diff, que é a distância Euclidiana.
- Compara a distância atual com a minDistance encontrada até agora. Se a distância atual for menor, atualiza minDistance e bestClusterIndex para o índice do cluster atual (j).
- clusterAssignments: Após iterar sobre todos os centróides, atribui o ponto de dado i ao bestClusterIndex (o índice do cluster com o centróide mais próximo).
- Retorna o array clusterAssignments com as atribuições de cluster para todos os pontos de dado.
Método updateCentroids: Recálculo dos centróides
Este método recalcula a posição dos centróides de cada cluster, calculando a média de todos os pontos atribuídos a cada cluster.
- newCentroids: Cria um novo INDArray para armazenar os novos centróides (recalculados).
- clusterCounts: Cria um array para contar quantos pontos foram atribuídos a cada cluster.
- Loop for: Itera sobre todos os pontos de dados.
- clusterIndex: Obtém o índice do cluster ao qual o i-ésimo ponto foi atribuído na etapa de atribuição.
- newCentroids.putRow: Soma o ponto de dado atual ao centróide correspondente no newCentroids. addiRowVector adiciona o data.getRow(i) (o ponto de dado) à linha clusterIndex de newCentroids. Na prática, estamos acumulando a soma de todos os pontos para cada cluster nos newCentroids.
- clusterCounts[clusterIndex]++;: Incrementa o contador de pontos para o cluster correspondente.
- Segundo loop for: Itera sobre cada cluster.
- Verifica se o cluster não está vazio (se tem pelo menos um ponto atribuído a ele).
- newCentroids.putRow: Calcula a média: Divide a soma acumulada de pontos para o cluster i (armazenada em newCentroids.getRow(i)) pelo número de pontos no cluster (clusterCounts[i]). O resultado dessa divisão (a média) se torna o novo centróide do cluster i, substituindo o valor anterior em newCentroids.putRow(i, …)
- Se um cluster estiver vazio (nenhum ponto atribuído a ele em uma iteração), existem várias estratégias:
- Manter o Centróide Anterior: (Opção Implementada no Código): Simplesmente mantemos o centróide na mesma posição que estava antes.
- Reinicializar Centróide Aleatoriamente: Poderíamos escolher um novo ponto de dado aleatório para ser o centróide do cluster vazio.
- Estratégias Mais Sofisticadas: Existem outras abordagens mais avançadas para lidar com clusters vazios. Para este exemplo simplificado, manter o centróide anterior é suficiente.
Método fit: Execução principal do KMeans (treinamento)
Este é o método principal que executa o algoritmo KMeans iterativamente até a convergência ou atingir o número máximo de iterações.
- initializeCentroids: Chama o método para inicializar os centróides aleatoriamente.
- Loop for: Loop principal de iterações do KMeans.
- clusterAssignments: Chama o método para atribuir todos os pontos aos clusters com base nos centróides atuais.
- oldCentroids: Cria uma cópia dos centróides atuais (centroids) antes de recalcular os novos. Usamos centroids.dup() para fazer uma cópia profunda (deep copy) do INDArray, para que as modificações em centroids no próximo passo não alterem os oldCentroids.
- updateCentroids: Chama o método para recalcular os centróides com base nas atribuições de cluster da iteração atual, atualizando centroids com as novas posições.
- Verificação de Convergência:
- centroidMovement: Calcula o “movimento” total dos centróides entre a iteração anterior e a atual. O calculateCentroidMovement (método auxiliar privado – veja abaixo) calcula a distância Euclidiana entre os oldCentroids e newCentroids.
- Verifica se o centroidMovement é menor que um valor muito pequeno (ex: 1e-6). Se for, significa que os centróides quase não se moveram, o que indica que o KMeans convergiu para uma solução estável.
- Se o KMeans convergiu, sai do loop de iterações.
- calculateCentroidMovement: Método Auxiliar Privado para Calcular o Movimento dos Centróides:
- Calcula a diferença entre os centróides antigos (oldCentroids) e os novos (newCentroids).
- Retorna a distância Euclidiana (norma L2) dessa diferença, que quantifica o “movimento” geral dos centróides.
Método predict: Prever clusters para novos pontos (após o treinamento)
Este método, após o treinamento do KMeans (fit()), pode ser usado para atribuir novos pontos de dados aos clusters, com base nos centróides aprendidos durante o treinamento.
Simplesmente reutiliza o método assignClusters, mas agora utilizando os centroids que foram aprendidos (encontrados) durante o treinamento (fit()). Ou seja, atribuímos os novos pontos de dados aos clusters mais próximos com base nos centróides já estabelecidos.
Método calculateSquaredErrors: Custo do agrupamento (Soma dos erros quadrados)
Este método calcula a Soma dos Erros Quadrados (Sum of Squared Errors – SSE), também conhecida como Inertia. O SSE é uma métrica comum para avaliar a qualidade de um agrupamento KMeans. Um SSE menor indica um agrupamento melhor (clusters mais coesos).
- totalSquaredError: Inicializa a variável para acumular a Soma dos Erros Quadrados (SSE).
- Loop for: Itera sobre cada ponto de dado.
- clusterIndex: Obtém o índice do cluster ao qual o i-ésimo ponto foi atribuído.
- centroid: Obtém o centróide do cluster correspondente.
- diff: Calcula o vetor diferença entre o ponto de dado e o centróide do seu cluster.
- squaredError: Calcula o quadrado da distância Euclidiana entre o ponto e seu centróide.
- totalSquaredError: Acumula o erro quadrático na variável totalSquaredError.
Classe para carregar dados de clientes
Vamos criar uma classe CustomerData.java para carregar e preparar os dados de clientes do arquivo CSV. Esta classe será similar à RealEstateData.java do post anterior, mas adaptada para o formato do nosso CSV de dados de clientes.
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.factory.Nd4j;
public class CustomerData {
public static Pair<INDArray, INDArray> loadCustomerDataFromCSV(String csvFileName, String featureColumnName1, String featureColumnName2) throws IOException {
List<Double> featureList1 = new ArrayList<>();
List<Double> featureList2 = new ArrayList<>();
int featureColumnIndex1 = -1;
int featureColumnIndex2 = -1;
// Usando ClassLoader para acessar o recurso a partir de src/main/resources
ClassLoader classLoader = CustomerData.class.getClassLoader();
InputStream inputStream = classLoader.getResourceAsStream(csvFileName); // Passa apenas o nome do arquivo
if (inputStream == null) {
throw new IOException("Arquivo CSV não encontrado em src/main/resources: " + csvFileName);
}
try (BufferedReader br = new BufferedReader(new InputStreamReader(inputStream))) {
String line = br.readLine(); // Lê o cabeçalho
String[] headers = line.split(","); // Assume CSV com vírgula como separador
// Encontra os índices das colunas de feature e target no cabeçalho
for (int i = 0; i < headers.length; i++) {
if (headers[i].trim().equalsIgnoreCase(featureColumnName1)) {
featureColumnIndex1 = i;
} else if (headers[i].trim().equalsIgnoreCase(featureColumnName2)) {
featureColumnIndex2 = i;
}
}
if (featureColumnIndex1 == -1 || featureColumnIndex2 == -1) {
throw new IllegalArgumentException("Colunas de feature não encontradas no CSV.");
}
while ((line = br.readLine()) != null) {
String[] values = line.split(",");
featureList1.add(Double.parseDouble(values[featureColumnIndex1].trim())); // Converte feature 1 para double
featureList2.add(Double.parseDouble(values[featureColumnIndex2].trim())); // Converte feature 2 para double
}
}
// Converte List<Double> para INDArray (matrizes ND4J)
int numSamples = featureList1.size();
double[][] featuresArray = new double[numSamples][2]; // Matriz de features (DUAS colunas: Gasto Anual e Idade)
for (int i = 0; i < numSamples; i++) {
featuresArray[i][0] = featureList1.get(i); // Preenche feature 1
featuresArray[i][1] = featureList2.get(i); // Preenche feature 2
}
INDArray featuresNDArray = Nd4j.create(featuresArray); // Cria INDArray de features (tipo DOUBLE explícito)
return new Pair<>(featuresNDArray, null); // Retorna um Pair contendo as matrizes de features (targets não são usados no KMeans, então passamos null)
}
// Classe auxiliar Pair (simples)
public static class Pair<F, S> {
public final F first;
public final S second;
public Pair(F first, S second) {
this.first = first;
this.second = second;
}
}
}- loadCustomerDataFromCSV: Carrega dados do arquivo CSV (localizado em src/main/resources). Este método é similar ao loadDataFromCSV do post anterior, mas adaptado para ler duas colunas de features (“Gasto_Anual” e “Idade”).
- Retorna um Pair contendo o INDArray de features (featuresNDArray). Como KMeans é um algoritmo não supervisionado, não precisamos de targets (rótulos) aqui, então o segundo elemento do Pair é null.
Criando a visualização com JFreeChart 🎨📊
Agora, a cereja do bolo! Vamos criar uma nova classe Java, KMeansVisualization.java, para gerar o gráfico de dispersão 2D dos clusters KMeans usando JFreeChart! Prepare-se para a magia visual! ✨
import java.awt.Color;
import java.awt.Rectangle;
import java.util.Random;
import org.jfree.chart.ChartFactory;
import org.jfree.chart.ChartPanel;
import org.jfree.chart.JFreeChart;
import org.jfree.chart.plot.PlotOrientation;
import org.jfree.chart.plot.XYPlot;
import org.jfree.chart.renderer.xy.XYLineAndShapeRenderer;
import org.jfree.chart.ui.ApplicationFrame;
import org.jfree.data.xy.XYSeries;
import org.jfree.data.xy.XYSeriesCollection;
import org.jfree.ui.RefineryUtilities;
import org.nd4j.linalg.api.ndarray.INDArray;
public class KMeansVisualization extends ApplicationFrame {
private static final long serialVersionUID = 1L;
public KMeansVisualization(String title, INDArray data, int[] clusterAssignments, INDArray centroids, int k) {
super(title);
setContentPane(createChartPanel(data, clusterAssignments, centroids, k));
}
private ChartPanel createChartPanel(INDArray data, int[] clusterAssignments, INDArray centroids, int k) {
XYSeriesCollection dataset = createDataset(data, clusterAssignments, centroids, k);
JFreeChart chart = createChart(dataset);
return new ChartPanel(chart);
}
private XYSeriesCollection createDataset(INDArray data, int[] clusterAssignments, INDArray centroids, int k) {
XYSeriesCollection dataset = new XYSeriesCollection();
Random randomColor = new Random();
Color[] clusterColors = new Color[k]; // Cores para cada cluster
// Gerar cores aleatórias distintas para cada cluster
for (int i = 0; i < k; i++) {
clusterColors[i] = new Color(randomColor.nextInt(256), randomColor.nextInt(256), randomColor.nextInt(256));
}
// Criar Series para os pontos de dados (coloridos por cluster)
for (int clusterIndex = 0; clusterIndex < k; clusterIndex++) {
XYSeries series = new XYSeries("Cluster " + clusterIndex);
for (int i = 0; i < data.rows(); i++) {
if (clusterAssignments[i] == clusterIndex) {
// Adiciona ponto (Gasto Anual, Idade)
series.add(data.getDouble(i, 0), data.getDouble(i, 1));
}
}
dataset.addSeries(series); // Adiciona a Serie ao Dataset
}
// Criar Series para os Centróides (marcadores maiores e cor preta)
XYSeries centroidSeries = new XYSeries("Centróides");
for (int i = 0; i < k; i++) {
centroidSeries.add(centroids.getDouble(i, 0), centroids.getDouble(i, 1)); // Adiciona centróide (Gasto Anual, Idade)
}
dataset.addSeries(centroidSeries); // Adiciona a Serie dos Centróides
return dataset;
}
private JFreeChart createChart(XYSeriesCollection dataset) {
JFreeChart chart = ChartFactory.createScatterPlot(
"Segmentação de Clientes com KMeans", // Título do gráfico
"Gasto Anual", // Rótulo eixo X
"Idade", // Rótulo eixo Y
dataset, // Dataset
PlotOrientation.VERTICAL,
true, // Usar legenda
true,
false
);
// Customização Visual do Gráfico
XYPlot plot = (XYPlot) chart.getPlot();
plot.setBackgroundPaint(Color.WHITE); // Fundo branco
plot.setDomainGridlinePaint(Color.LIGHT_GRAY); // Linhas de grade cinza claro
plot.setRangeGridlinePaint(Color.LIGHT_GRAY);
XYLineAndShapeRenderer renderer = new XYLineAndShapeRenderer();
for (int seriesIndex = 0; seriesIndex < dataset.getSeriesCount(); seriesIndex++) {
renderer.setSeriesShapesVisible(seriesIndex, true); // Pontos de dados visíveis
renderer.setSeriesShapesFilled(seriesIndex, true);
// Linhas entre os pontos INVISÍVEIS (scatter plot)
renderer.setSeriesLinesVisible(seriesIndex, false);
}
// Cores e Formatos para Clusters (cores aleatórias já definidas no createDataset)
Random randomColor = new Random();
Color[] clusterColors = new Color[dataset.getSeriesCount() -1 ]; // Ignora a última série (centróides)
for (int i = 0; i < clusterColors.length; i++) {
clusterColors[i] = new Color(randomColor.nextInt(256), randomColor.nextInt(256), randomColor.nextInt(256));
renderer.setSeriesPaint(i, clusterColors[i]); // Cores aleatórias para clusters
}
// Formato dos Centróides (Série separada, cor preta, marcador maior)
int centroidSeriesIndex = dataset.getSeriesCount() - 1; // Índice da série de centróides (a última série adicionada)
renderer.setSeriesShape(centroidSeriesIndex, new Rectangle(8, 8)); // Marcador de retângulo maior para centróides
renderer.setSeriesPaint(centroidSeriesIndex, Color.BLACK); // Cor preta para centróides
renderer.setSeriesShapesVisible(centroidSeriesIndex, true); // Centróides visíveis
renderer.setSeriesShapesFilled(centroidSeriesIndex, true);
renderer.setSeriesLinesVisible(centroidSeriesIndex, false); // Sem linhas para centróides (só marcadores)
plot.setRenderer(renderer); // Aplica o Renderer customizado ao Plot
return chart; // Retorna o gráfico JFreeChart criado
}
public void displayChart() {
this.pack();
RefineryUtilities.centerFrameOnScreen(this);
this.setVisible(true); // Exibe o gráfico em uma janela
}
}Na classe KMeansVisualization.java:
- Extensão de ApplicationFrame: A classe KMeansVisualization estende ApplicationFrame da JFreeChart para criar uma janela JFrame para exibir o gráfico.
- Construtor KMeansVisualization(…): Recebe o título da janela, os dados dos clientes (data), as atribuições de cluster (clusterAssignments), os centróides (centroids) e o número de clusters (k). Chama createChartPanel para criar o painel do gráfico e o define como o conteúdo do JFrame.
- createChartPanel(…): Chama createDataset() para criar o dataset de dados JFreeChart a partir dos dados do KMeans, e então chama createChart() para criar o objeto JFreeChart em si, e finalmente retorna um ChartPanel (painel que contém o gráfico) pronto para ser exibido em um JFrame.
- createDataset(…): Cria o dataset de dados para o JFreeChart a partir dos resultados do KMeans.
- dataset: Cria um XYSeriesCollection, que é um container para as séries de dados que serão plotadas no gráfico JFreeChart.
- Cores Aleatórias para Clusters: Gera um array de cores aleatórias distintas (clusterColors) para cada cluster, para que cada cluster seja visualizado com uma cor diferente no gráfico.
- Criação de Séries para os Pontos de Dados (Coloridos por Cluster):
- Loop externo for: Itera sobre cada cluster.
- series: Cria uma nova XYSeries para cada cluster. XYSeries representa uma série de dados XY (pontos no gráfico). O nome da série é definido como “Cluster ” + índice do cluster.
- Loop interno for: Itera sobre todos os pontos de dados (clientes).
- Verifica se o ponto de dado i pertence ao clusterIndex atual.
- series.add: Adiciona o ponto de dado (Gasto Anual, Idade) à série do cluster correspondente. data.getDouble(i, 0) pega o valor da feature “Gasto Anual” do ponto i, e data.getDouble(i, 1) pega o valor da feature “Idade” do ponto i. Com isso, criamos um ponto (x, y) = (Gasto Anual, Idade) para o gráfico de dispersão.
- dataset.addSeries: Adiciona a série de dados do cluster ao XYSeriesCollection.
- Criação de Série para os Centróides (Marcadores Distintos):
- centroidSeries: Cria uma XYSeries separada para os centróides. Isso é importante para podermos formatar os centróides de forma diferente dos pontos de dados normais (cor, formato do marcador, etc.).
- Loop for: Itera sobre os centróides.
- centroidSeries.add: Adiciona cada centróide à centroidSeries, usando as coordenadas (Gasto Anual, Idade) do centróide.
- dataset.addSeries: Adiciona a série de centróides ao XYSeriesCollection.
- createChart: Cria o objeto JFreeChart (o gráfico em si) a partir do dataset.
- ChartFactory.createScatterPlot(…): Utiliza ChartFactory.createScatterPlot para criar um gráfico de dispersão. Define o título, rótulos dos eixos X e Y, o dataset, orientação do plot, se deve exibir legenda, tooltips e URLs.
- Customização Visual do Gráfico (Cores, Formatos, etc.):
- plot: Obtém o XYPlot (a área de plotagem do gráfico) do objeto JFreeChart.
- plot.setBackgroundPaint(Color.WHITE);: Define o fundo do plot como branco.
- plot.setDomainGridlinePaint(Color.LIGHT_GRAY); e plot.setRangeGridlinePaint(Color.LIGHT_GRAY);: Define a cor das linhas de grade como cinza claro.
- renderer: Cria um XYLineAndShapeRenderer. Este Renderer é responsável por como os pontos e linhas são desenhados em um gráfico XY. Vamos customizá-lo para nosso gráfico de dispersão.
- renderer.setSeriesShapesVisible e renderer.setSeriesShapesFilled; renderer.setSeriesLinesVisible(0, false);: Para a Série de Dados dos Clusters (pontos de dados), define para tornar os marcadores de forma visíveis (setSeriesShapesVisible(0, true)) e preenchidos (setSeriesShapesFilled(0, true)) e para tornar as linhas entre os pontos invisíveis (setSeriesLinesVisible(0, false)). Isso garante que tenhamos um verdadeiro gráfico de dispersão (scatter plot), onde vemos apenas os pontos, e não linhas conectando-os. Usamos índice 0 para configurar a primeira série adicionada ao dataset (que são os pontos de dados dos clusters – a série de centróides será a última série adicionada, com índice diferente).
- Cores para Clusters (Aleatórias): Define um array clusterColors com cores aleatórias. Loop for para percorrer as séries de dados dos clusters (ignorando a última série, que é a de centróides) e usar renderer.setSeriesPaint(i, clusterColors[i]) para atribuir uma cor diferente a cada cluster (cores geradas aleatoriamente no createDataset).
- Formato dos Centróides (Marcadores Distintos):
- centroidSeriesIndex: Obtém o índice da última série adicionada ao dataset, que é a série dos Centróides. (Adicionamos a série dos centróides depois das séries dos clusters).
- renderer.setSeriesShape: Define a forma dos marcadores dos centróides como um retângulo maior (8×8 pixels) para que eles se destaquem no gráfico.
- renderer.setSeriesPaint: Define a cor dos centróides como preto.
- renderer.setSeriesShapesVisible; renderer.setSeriesShapesFilled; renderer.setSeriesLinesVisible: Semelhante aos pontos de dados dos clusters, torna os marcadores dos centróides visíveis e preenchidos, e as linhas invisíveis (apenas marcadores para centróides).
- plot.setRenderer: Aplica o renderer customizado ao plot, definindo as cores, formas e estilos dos pontos e linhas no gráfico.
- displayChart(): Método para exibir o gráfico em uma janela JFrame. this.pack() ajusta o tamanho da janela para caber o gráfico, RefineryUtilities.centerFrameOnScreen(this) centraliza a janela na tela, e this.setVisible(true) torna a janela visível.
- Dependência JFreeChart: Para usar esta classe, você precisa adicionar a dependência JFreeChart ao seu arquivo pom.xml:
</dependencies>
<!-- Outras dependências já adicionadas anteriormente... -->
<dependency>
<groupId>org.jfree</groupId>
<artifactId>jfreechart</artifactId>
<version>1.5.3</version>
</dependency>
<dependency>
<groupId>org.jfree</groupId>
<artifactId>jcommon</artifactId>
<version>1.0.24</version>
</dependency>
</dependencies>
Executando o KMeans para Segmentação de Clientes 🚀📊
Finalmente, vamos criar a classe Main.java para usar a classe KMeansClassifier e segmentar nossos dados de clientes.
import java.io.IOException;
import org.nd4j.linalg.api.ndarray.INDArray;
public class Main {
public static void main(String[] args) throws IOException {
// 1. Carregar Dados de Clientes do CSV (Duas features: Gasto Anual e Idade)
String csvFilePath = "dados_clientes_simples.csv";
CustomerData.Pair<INDArray, INDArray> data = CustomerData.loadCustomerDataFromCSV(
csvFilePath, "Gasto_Anual", "Idade"); // Nomes das colunas de features no CSV
INDArray customerFeatures = data.first; // Features dos clientes (Gasto Anual e Idade)
// 2. Criar Classificador KMeans (k=3 clusters, máximo 100 iterações)
int k = 3; // Número de clusters desejado (segmentos de clientes)
int maxIterations = 100;
KMeansClassifier kMeansClassifier = new KMeansClassifier(k, maxIterations);
// 3. Treinar o KMeans (Agrupar os clientes)
System.out.println("--- Treinamento do KMeans ---");
kMeansClassifier.fit(customerFeatures); // Treina o KMeans com as features dos clientes
INDArray centroids = kMeansClassifier.centroids; // Recupera os centróides aprendidos
System.out.println("\nCentróides Finais:\n" + centroids);
// 4. Obter Atribuições de Cluster para cada Cliente
int[] clusterAssignments = kMeansClassifier.predict(customerFeatures); // Prever clusters para os dados de clientes
System.out.println("\n--- Atribuições de Cluster para Cada Cliente ---");
for (int i = 0; i < clusterAssignments.length; i++) {
System.out.println("Cliente " + (i + 1) + ": Cluster " + clusterAssignments[i]); // Imprime o cluster de cada cliente
}
// 5. Calcular o Custo do Agrupamento (SSE - Soma dos Erros Quadrados)
double cost = kMeansClassifier.calculateSquaredErrors(customerFeatures, centroids, clusterAssignments); // Calcula o custo
System.out.println("\nCusto Total do Agrupamento (SSE): " + String.format("%.2f", cost));
// 6. Criar e Exibir o Gráfico KMeans
System.out.println("\n--- Exibindo Visualização Gráfica dos Clusters KMeans (JFreeChart) ---");
KMeansVisualization visualization = new KMeansVisualization(
"Segmentação de Clientes KMeans", // Título da Janela
customerFeatures, // Dados dos Clientes (features)
clusterAssignments, // Atribuições de Cluster
centroids, // Centróides
k // Número de Clusters
);
visualization.displayChart(); // Exibe o gráfico em uma janela JFrame
}
}- Carregar Dados de Clientes:
- Define o caminho do arquivo CSV de clientes (csvFilePath).
- CustomerData.loadCustomerDataFromCSV(…): Carrega os dados de clientes do CSV, especificando as colunas de features “Gasto_Anual” e “Idade”.
- customerFeatures: Obtém o INDArray de features dos clientes.
- Criar Classificador KMeans:
- k: Define o número de clusters desejado (3 segmentos de clientes, neste exemplo).
- kMeansClassifier: Cria uma instância do KMeansClassifier com 3 clusters e máximo de 100 iterações.
- Treinar KMeans:
- kMeansClassifier.fit: Chama o método fit() para treinar o KMeans com os dados de clientes.
- centroids: Após o treinamento, recupera os centroids aprendidos pelo KMeans.
- Obter Atribuições de Cluster:
- clusterAssignments: Usa o método predict() para atribuir cada cliente a um dos clusters, com base nos centróides aprendidos.
- Loop for: Itera sobre as clusterAssignments e imprime o cluster atribuído para cada cliente.
- Calcular Custo do Agrupamento (SSE):
- cost: Calcula o custo do agrupamento (SSE) usando o método calculateSquaredErrors().
- Visualização
- visualization: Cria uma instância da classe KMeansVisualization que criamos anteriormente para exibir os clusters e centroides em um gráfico.
Antes de executar Main.java
- Crie o arquivo
dados_clientes_simples.csvcom os dados de clientes (veja abaixo) na pastasrc/main/resourcesdo seu projeto Java, com o seguinte conteúdo:
Gasto_Anual,Idade
32122,26
12693,59
39180,27
26420,48
29390,43
9793,63
9048,57
23153,41
26296,23
27347,27
13432,25
2522,66
5602,32
12210,41
7561,60
18841,30
16984,30
23021,43
7746,58
9448,68
34306,32
1000,60
21909,32
5047,52
23332,37
9164,54
31711,20
14955,53
8856,66
21412,40
7494,49
7786,69
11295,26
13547,25
12252,56
11118,31
10302,67
9883,33
16770,34
32805,38
22544,24
33309,26
29582,38
24684,35
12503,52
15194,65
16693,55
38440,48
7430,55
7470,51
13918,58
19008,53
17974,27
15364,21
21638,37
28417,24
23996,37
10689,57
9081,51
11766,41
28024,28
9187,60
32726,48
28265,47
11242,31
9212,44
13860,58
16064,47
14848,30
13094,52
6148,61
14686,58
12640,22
15280,68
39097,43
16761,46
2206,42
10888,42
11414,56
19445,48
6762,56
27550,43
16127,41
30059,35
19398,39
14684,69
7313,64
7824,58
19894,28
25660,27
19359,33
17962,31
16377,45
5291,64
24409,43
4663,54
7731,21
8494,60
23721,33
15079,68
10356,43
11807,32
33669,28
7994,68
19720,24
9462,57
14066,49
28169,49
31979,29
5809,55
22973,22
24255,34
16907,66
28206,35
35168,32
6773,31
21232,33
16948,61
34450,26
18094,44
16843,42
6998,20
12769,64
3765,63
23987,21
1000,51
25778,46
21372,25
14418,41
8217,56
22439,48
13709,55
12477,33
22180,47
7676,62
43050,35
6300,56
10842,37
25131,33
3539,60
10522,38
28631,37
18460,26
18851,29
16282,20
6841,54
27300,29
13200,50
21081,35
26400,32
21216,42
11408,58
1000,51
10117,35
24098,43
23042,30
28699,31
20743,40
20420,37
12069,66
13146,66
33689,39
20336,42
11918,63
35116,24
21213,33
1753,62
16588,31
5652,50
33129,42
18257,25
37242,29
23668,20
9096,50
16387,49
19603,46
2964,54
10459,24
15670,67
11994,56
11856,30
24995,28
4377,38
7916,69
13678,67
17555,41
15581,69
22401,38
6883,66
26802,24
14132,63
24644,25
9562,59
7941,60
40400,28
24424,46
14698,42
14484,35
9857,52
8093,20
17346,22
12352,48
7307,30
14549,57
29790,45
28595,43
6314,51
9192,62
14497,65
25887,43
13949,28
39039,23
17037,35
9083,54
15380,54
19363,49
4655,51
16636,63
26880,28
17889,45
11048,48
29147,30
29025,26
18748,26
31729,47
8745,52
31926,22
26738,25
8603,30
17761,37
43044,36
42176,43
6401,65
24767,47
10447,66
11065,59
6147,68
3923,58
2831,36
20037,48
14120,52
5795,56
18680,43
8816,56
22992,30
22045,28
10037,45
4718,64
1370,64
23391,41
24205,26
18126,32
28863,31
23572,21
13022,67
15444,69
13917,52
31044,41
32223,21
18253,21
31089,38
36574,32
16874,33
31483,39
11278,46
3188,54
3425,50
22743,45
15344,30
5118,68
18519,37
16322,22
22659,41
15281,61
12071,46
12000,63
1000,67
16593,46
21844,39
2405,69
13601,64
11684,68
6692,50
8309,67
11996,33
5392,38
28220,23
4017,57
13465,65
13768,61
35780,20
11317,63
3297,59
14057,65
15635,56
20990,48
4327,48
13911,32
24948,26
11150,65
6568,52
6544,64
9999,26
29936,21
15778,35
31803,41
5004,59
11106,50
29122,29
13138,54
26502,23
8324,55
6953,46
32773,45
16271,35
18220,24
11261,69
24551,28
1000,46
14415,33
5705,68
27485,26
11434,60
7931,65
1000,61
6015,34
18312,69
13827,20
11495,60
7647,42
21552,34
39005,40
22036,40
25356,46
11077,50
14201,67
29699,25
15625,45
7406,63
18938,24
11630,64
6554,50
5500,66
6801,69
10196,55
36352,26
15628,25
11799,46
1763,63
31097,38
22545,63
6463,56
10458,34
13152,34
28232,29
7145,58
24144,37
31757,36
5254,29
28363,41
33275,37
18391,30
15281,49
18254,28
14193,37
1000,69
26606,31
11008,61
12678,68
7882,40
26773,30
4844,58
12005,60
33614,39
17983,63
12113,56
15648,35
6992,65
6159,52
18601,63
5857,62
16247,59
25668,24
8669,32
9513,47
19181,33
13802,66
10977,48
26356,21
17441,21
30312,25
14735,27
7681,40
25035,35
1000,53
7222,66
6388,30
21126,26
15087,48
9471,69
11720,58
10746,47
35179,23
21097,30
16709,47
22089,47
30672,37
4907,63
24120,25
10156,25
25661,35
22826,30
16860,34
5996,42
28137,39
24219,40
4177,68
40966,21
26091,45
10495,33
4647,66
16295,69
11879,61
34963,45
13798,54
14148,56
19495,64
21527,68
38512,30
18466,61
14740,69
16800,29
21044,67
21758,27
3550,54
24808,38
22382,28
7360,61
11692,51
11346,64
4910,43
7336,51
25796,40
30289,42
19799,38
14189,55
14177,56
27340,48
7846,55
12224,24
2610,61
40854,28
1000,35
29177,22
25328,26
11693,42
5713,57
15481,52
15848,52
13349,64
16279,56
29932,34
34947,23
4266,59
8149,50
25698,47
21992,28
11455,65
19425,66
44831,44
19433,29
7580,55
7054,67
19823,31
24807,21
3875,69
11072,58
7471,52
31977,47
4352,61
4762,50
21904,46
27354,47
14113,21
35021,47
5492,33
24489,25
26908,31
37799,45
11957,45
17742,36
6879,64
14634,68
12788,50
24060,33
14782,59
5484,52
16368,68
1000,32
15007,58
- Certifique-se de ter as classes descritas acima criadas no seu projeto.
- Mantenha as dependências ND4J, Deeplearning4j e JFreeChart configuradas no seu pom.xml.
Execute Main.java! Você deverá ver a saída do treinamento do KMeans, os centróides finais, as atribuições de cluster para cada cliente, o custo do agrupamento (SSE) e a visualização gráfica dos clusters!
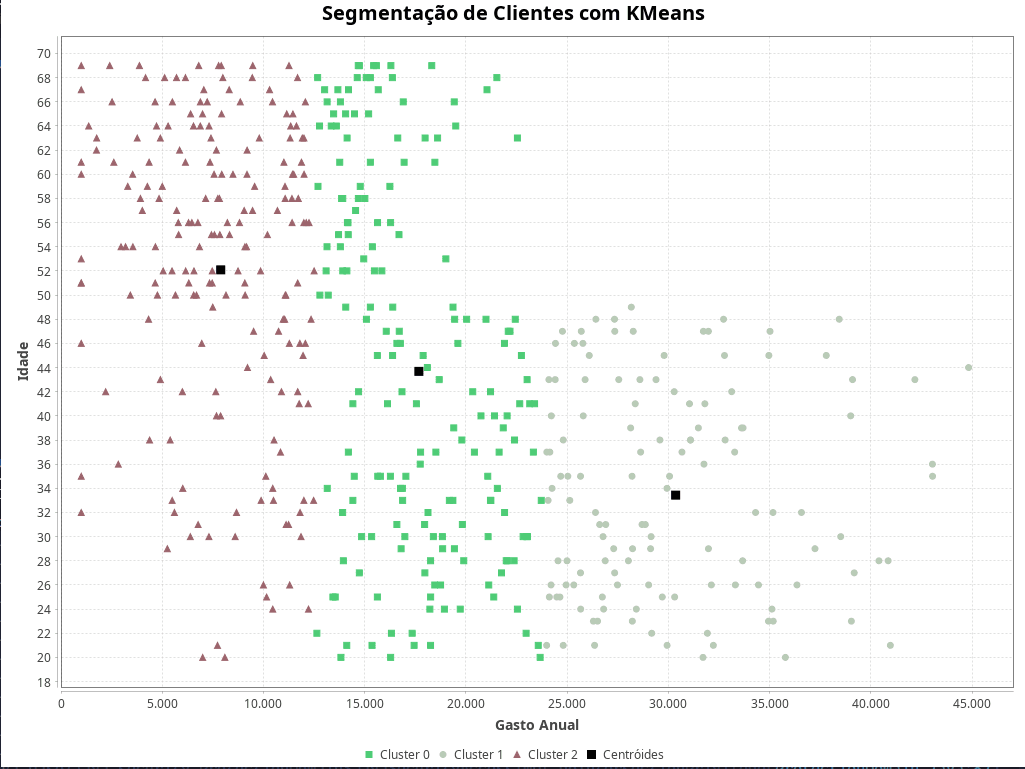
Exemplo de saída do terminal (os números podem variar):
--- Treinamento do KMeans ---
Iteração 0, Movimento dos Centróides: 3050,9145
Iteração 1, Movimento dos Centróides: 407,6424
Iteração 2, Movimento dos Centróides: 283,9434
Iteração 3, Movimento dos Centróides: 333,2418
Iteração 4, Movimento dos Centróides: 249,0272
Iteração 5, Movimento dos Centróides: 326,1808
Iteração 6, Movimento dos Centróides: 181,8274
Iteração 7, Movimento dos Centróides: 84,0151
Iteração 8, Movimento dos Centróides: 84,3309
Iteração 9, Movimento dos Centróides: 0,0000
KMeans Convergiu na Iteração 9
Centróides Finais:
[[ 7691.8615, 52.4205],
[ 3.0162e4, 33.7661],
[ 1.748e4, 44.0166]]
--- Atribuições de Cluster para Cada Cliente ---
Cliente 1: Cluster 1
Cliente 2: Cluster 2
Cliente 3: Cluster 1
Cliente 4: Cluster 1
Cliente 5: Cluster 1
...
Cliente 495: Cluster 1
Cliente 496: Cluster 2
Cliente 497: Cluster 0
Cliente 498: Cluster 2
Cliente 499: Cluster 0
Cliente 500: Cluster 2
Custo Total do Agrupamento (SSE): 6949288458,69Parabéns! 🎉 Você construiu um algoritmo KMeans funcional em Java e aplicou-o para segmentar clientes com base em seus gastos e idades! Você viu o poder do KMeans em ação para revelar padrões e agrupar dados de forma inteligente.
Próximos passos e expandindo seu domínio de agrupamento com IA em Java… 🚀🧙♂️
Neste artigo, você deu mais um passo gigante e dominou o KMeans em Java! Você aprendeu os fundamentos do algoritmo de clustering, implementou o KMeans passo a passo em Java, aplicou-o a um problema prático de segmentação de clientes e visualizou os resultados (textualmente no console para este exemplo!).
No próximo post, vamos mergulhar no fascinante mundo do Processamento de Linguagem Natural (PLN) em Java! Construiremos um analisador de sentimentos para tweets (ou X, ou seja lá como chamam agora)! Prepare-se para processar texto em Java, aplicar técnicas de PLN e usar Machine Learning para analisar sentimentos em tweets e dominar a opinião pública! 🐦🗣️
Gostou deste post? Compartilhe com seus amigos desenvolvedores Java que também querem dominar a Inteligência Artificial! Deixe seu comentário abaixo com dúvidas, sugestões e ideias para os próximos posts da série. Vamos construir juntos essa comunidade de IA em Java!