

E aí, pessoal! Preparados para turbinar nossos robôs de conversa? 😎
Nos últimos posts aprendemos prever, classificar e agrupar dados, clusterizar quando não conhecemos as categorias, e também demos os primeiros passos na utilização de visão computacional. Agora, chegou a hora de construir um chatbot inteligente.
Se você quer que seu chatbot realmente entenda o que os usuários dizem, em vez de apenas reagir a regras fixas, e que seja capaz de ter conversas mais flexíveis e naturais, prepare-se para esta aventura! Vamos criar um chatbot que usa Inteligência Artificial para classificar as intenções dos usuários e responder de forma mais inteligente e contextualizada. É hora de dar um upgrade de IA nos nossos robôs de conversa! 🧠
Chatbots inteligentes: Entendendo o que se esconde por trás das palavras 🤯
Primeiramente, qual a diferença entre um chatbot baseado em regras e um chatbot inteligente com IA? A chave está na capacidade de “entender” a linguagem humana. Chatbots baseados em regras são como “papagaios”: eles repetem frases pré-programadas quando detectam certas palavras-chave, mas não compreendem o significado do que está sendo dito.
Chatbots Inteligentes, por outro lado, buscam simular a compreensão humana da linguagem. Eles usam técnicas de Processamento de Linguagem Natural (PLN) e Aprendizado de Máquina (Machine Learning) para:
- Entender a Intenção do Usuário: Identificar o que o usuário quer dizer, qual é o objetivo da mensagem, qual ação ele espera que o chatbot realize. Por exemplo, se o usuário digita “Qual a previsão do tempo para amanhã?”, a intenção é clara: obter informações sobre a previsão do tempo.
- Reconhecer Entidades: Identificar informações relevantes na mensagem do usuário, como nomes de pessoas, lugares, datas, horários, produtos, etc. No exemplo anterior, a entidade é “amanhã” (data) e, implicitamente, a localização (que pode ser inferida do contexto ou perguntada ao usuário).
- Gerar Respostas Dinâmicas e Contextuais: Com base na intenção e nas entidades reconhecidas, o chatbot pode gerar respostas mais relevantes, personalizadas e que fazem sentido dentro do contexto da conversa. Em vez de apenas exibir uma resposta genérica, o chatbot pode fornecer informações específicas sobre a previsão do tempo para a data e localidade desejadas.
- Aprender e Melhorar Continuamente: Chatbots com IA podem ser treinados com grandes volumes de dados de conversas (datasets) e podem aprender com as interações com os usuários, melhorando suas respostas e sua capacidade de entender a linguagem humana ao longo do tempo.
Nosso chatbot inteligente: Classificação de intenções com Machine Learning 🎯
Para construir nosso Chatbot Inteligente, vamos focar em uma técnica fundamental: Classificação de Intenções. A ideia é treinar um modelo de Machine Learning para classificar as mensagens dos usuários em diferentes categorias de intenção.
Os passos que vamos seguir são:
- Definir as Intenções: Vamos criar uma lista de intenções que nosso chatbot será capaz de reconhecer. Por exemplo: saudacao, despedida, agradecimento, pergunta_nome, pergunta_tempo, conversa_aleatoria, etc.
- Criar um Dataset de Treinamento: Vamos montar um conjunto de dados de treinamento, onde cada exemplo consiste em uma frase de usuário e a intenção correspondente. Exemplo:
- Frase: “Oi, tudo bem?” -> Intenção: saudacao
- Frase: “Qual é o seu nome?” -> Intenção: pergunta_nome
- Frase: “Até logo!” -> Intenção: despedida
- Extrair Características (Features) dos Textos: Precisamos transformar as frases de texto em algo que o modelo de Machine Learning possa entender e processar. Vamos usar uma técnica simples chamada Bag of Words (Saco de Palavras), que consiste em criar um vocabulário de todas as palavras do dataset e representar cada frase como um vetor de contagem de palavras.
- Treinar um Modelo de Classificação: Vamos usar um algoritmo de classificação de Machine Learning para treinar um modelo com o dataset preparado. Podemos usar um modelo simples como Naive Bayes ou Support Vector Machines (SVM).
- Implementar o Chatbot: Vamos criar o código do chatbot que irá:
- Receber a mensagem do usuário.
- Extrair as características da mensagem usando a mesma técnica do treinamento (Bag of Words).
- Usar o modelo treinado para prever a intenção da mensagem.
- Com base na intenção prevista, escolher uma resposta apropriada para o chatbot.
Mão na massa: Chatbot inteligente com classificação de intenções em Python! 💻
Chegou a hora de codificar nosso Chatbot Inteligente! Vamos usar Python e a biblioteca scikit-learn para Machine Learning, que já conhecemos dos posts anteriores.
Primeiro passo, importar as bibliotecas essenciais:
import nltk # Usaremos NLTK para tokenização básica (opcional, mas útil)
from nltk.stem import RSLPStemmer # Stemmer para português
from sklearn.feature_extraction.text import TfidfVectorizer # Vetorização TF-IDF (alternativa ao Bag of Words)
from sklearn.naive_bayes import MultinomialNB # Classificador Naive Bayes Multinomial
from sklearn.pipeline import Pipeline # Pipeline para organizar o fluxo de trabalho
from sklearn.model_selection import train_test_split # Para dividir dados em treino e teste
from sklearn.metrics import accuracy_score, classification_report # Métricas de avaliação
import random # Para escolher respostas aleatóriasPreparar o dataset de treinamento
Vamos criar nosso dataset de treinamento com frases de exemplo e suas intenções correspondentes. Você pode expandir este dataset com mais exemplos e intenções para tornar o chatbot mais robusto.
# Dataset de treinamento (frases e intenções)
dataset = [
("Olá", "saudacao"),
("Oi", "saudacao"),
("E aí?", "saudacao"),
("Tudo bem?", "saudacao"),
("Como vai você?", "saudacao"),
("Qual é o seu nome?", "pergunta_nome"),
("Quem é você?", "pergunta_nome"),
("Como te chamam?", "pergunta_nome"),
("Me diga seu nome", "pergunta_nome"),
("Obrigado", "agradecimento"),
("Valeu!", "agradecimento"),
("Muito obrigado!", "agradecimento"),
("Agradeço a ajuda", "agradecimento"),
("Tchau", "despedida"),
("Adeus", "despedida"),
("Até logo", "despedida"),
("Fui!", "despedida"),
("Previsão do tempo para hoje?", "pergunta_tempo"),
("Vai chover amanhã?", "pergunta_tempo"),
("Como está o clima?", "pergunta_tempo"),
("Temperatura em São Paulo", "pergunta_tempo"),
("Conte uma piada", "conversa_aleatoria"),
("Fale sobre você", "conversa_aleatoria"),
("O que você faz?", "conversa_aleatoria"),
("Me surpreenda!", "conversa_aleatoria"),
("...", "conversa_aleatoria"), # Mensagens genéricas/não reconhecidas
("Não entendi", "conversa_aleatoria"),
("?", "conversa_aleatoria"),
("", "conversa_aleatoria"), # Mensagem vazia
]
# Separar frases e intenções
frases, intencoes = zip(*dataset) # Descompactar lista de tuplas em duas tuplas
frases = list(frases) # Converter tuplas para listas (para scikit-learn)
intencoes = list(intencoes)Criar o pipeline de Machine Learning
Vamos usar um Pipeline do scikit-learn para organizar o fluxo de trabalho de processamento de texto e treinamento do modelo.
# Pipeline de Machine Learning
pipeline = Pipeline([
('tfidf', TfidfVectorizer(analyzer='word', stop_words=nltk.corpus.stopwords.words('portuguese'))), # Vetorização TF-IDF
('clf', MultinomialNB()), # Classificador Naive Bayes Multinomial
])- Pipeline([…]): Cria um pipeline, que é uma sequência de transformações e um estimador final.
- (‘tfidf’, TfidfVectorizer(…)): Primeiro passo do pipeline: vetorização TF-IDF (Term Frequency-Inverse Document Frequency).
- TfidfVectorizer(…): Cria um vetorizador TF-IDF. Alternativa ao Bag of Words, o TF-IDF dá mais peso a palavras que são importantes em um documento específico, mas não são muito comuns em todos os documentos.
- analyzer=’word’: Vetorizar por palavras (tokens).
- stop_words=nltk.corpus.stopwords.words(‘portuguese’): Remover stop words (palavras muito comuns e pouco informativas, como “de”, “a”, “o”, “que”, etc.) em português, usando a lista de stop words do NLTK para português. Para usar stop words em português, você precisa ter o NLTK instalado e os stopwords baixados (nltk.download(‘stopwords’)).
- (‘clf’, MultinomialNB()): Segundo passo do pipeline: classificador Naive Bayes Multinomial.
- MultinomialNB(): Escolhemos o classificador Naive Bayes Multinomial, que é um algoritmo simples e eficiente para classificação de texto, especialmente com features de contagem (como TF-IDF).
Dividir os dados em treino e teste
É importante dividir os dados em conjuntos de treino e teste para avaliar o desempenho do modelo em dados que ele não viu durante o treinamento.
# Dividir dados em treino e teste
frases_treino, frases_teste, intencoes_treino, intencoes_teste = train_test_split(
frases, intencoes, test_size=0.2, random_state=42 # 20% para teste, seed para reprodutibilidade
)- train_test_split(…): Divide os dados em 80% para treino e 20% para teste.
- test_size=0.2: Define a proporção de dados para teste (20%).
- random_state=42: Define uma semente aleatória para garantir que a divisão seja a mesma sempre que rodarmos o código (reprodutibilidade).
Treinar o modelo
Agora, vamos treinar o modelo de classificação usando o pipeline e os dados de treino.
# Treinar o modelo
pipeline.fit(frases_treino, intencoes_treino)- pipeline.fit(frases_treino, intencoes_treino): Treina o pipeline! O método fit() do pipeline faz duas coisas:
- Vetoriza as frases de treino: Aplica o TfidfVectorizer nas frases_treino para transformá-las em vetores TF-IDF.
- Treina o classificador: Usa os vetores TF-IDF das frases de treino e as intencoes_treino correspondentes para treinar o classificador MultinomialNB.
Avaliar o modelo
Vamos avaliar o desempenho do modelo nos dados de teste.
# Fazer previsões nos dados de teste
intencoes_preditas = pipeline.predict(frases_teste)
# Avaliar o modelo
acuracia = accuracy_score(intencoes_teste, intencoes_preditas)
print(f"Acurácia do modelo nos dados de teste: {acuracia:.2f}")
print("\nRelatório de Classificação:")
print(classification_report(intencoes_teste, intencoes_preditas))- intencoes_preditas = pipeline.predict(frases_teste): Fazer previsões! O método predict() do pipeline faz duas coisas:
- Vetoriza as frases de teste: Aplica o TfidfVectorizer nas frases_teste para transformá-las em vetores TF-IDF, usando o mesmo vocabulário e transformações aprendidas durante o treinamento.
- Classifica as frases de teste: Usa o classificador MultinomialNB treinado para prever a intenção de cada frase de teste, com base nos seus vetores TF-IDF.
- acuracia = accuracy_score(…): Calcula a acurácia do modelo, que é a proporção de intenções corretamente preditas nos dados de teste.
- print(f”Acurácia do modelo nos dados de teste: {acuracia:.2f}”): Imprime a acurácia.
- print(“\nRelatório de Classificação:”): Imprime um relatório de classificação mais detalhado, com precisão, recall, f1-score e suporte para cada intenção (classe).
Implementar o chatbot inteligente (usando o modelo treinado)
Agora, vamos criar a função do chatbot que usa o modelo treinado para prever intenções e gerar respostas.
# Respostas predefinidas para cada intenção
respostas = {
"saudacao": ["Olá! Tudo bem por aí? 😊", "Oi! Em que posso ajudar? 😉", "Olá! Que bom te ver por aqui! 😄"],
"pergunta_nome": ["Eu sou um chatbot inteligente em Python! 🤖", "Pode me chamar de Chatbot IA! 😉", "Não tenho um nome oficial, mas sou seu chatbot amigo! 😊"],
"agradecimento": ["De nada! 😊 Sempre que precisar, pode me chamar!", "Por nada! 😉 Fico feliz em ajudar!", "Disponha! 😊"],
"despedida": ["Tchau! Foi ótimo conversar contigo! 👋", "Até mais! 😉 Volte sempre!", "Tchauzinho! 😊"],
"pergunta_tempo": ["Desculpe, ainda não consigo te dar a previsão do tempo. 😅 Mas estou aprendendo!", "Que pena, não tenho essa informação no momento. 😔", "Ainda não fui treinado para responder sobre o clima! 😅"],
"conversa_aleatoria": ["Hmm, interessante... 🤔 Conte mais!", "Não sei bem sobre isso... 😅 Mas adoro conversar!", "Que assunto curioso! 😄", "Vamos mudar de assunto? 😉"],
"default": ["Desculpe, não entendi muito bem... 🤔 Poderia reformular sua pergunta? 😉", "Não tenho certeza se compreendi... 😅 Pode tentar de novo?", "Poderia repetir, por favor? 🙏"], # Resposta padrão para intenções não mapeadas explicitamente
}
def chatbot_inteligente(mensagem_usuario):
"""Chatbot inteligente com classificação de intenções usando Machine Learning."""
# Prever a intenção da mensagem do usuário usando o pipeline treinado
intencao_prevista = pipeline.predict([mensagem_usuario])[0] # predict() espera uma lista de frases, mesmo que seja só uma
# Escolher resposta aleatória para a intenção prevista
if intencao_prevista in respostas: # Se tiver resposta predefinida para a intenção
resposta = random.choice(respostas[intencao_prevista])
else: # Se a intenção não estiver mapeada em respostas (fallback para default)
resposta = random.choice(respostas["default"]) # Usar resposta "default"
return resposta
# Loop principal do chatbot inteligente (interação com o usuário)
print("Chatbot Inteligente em Python com IA iniciado! Digite 'tchau' ou 'adeus' para sair.")
while True:
mensagem_usuario = input("Você: ")
if mensagem_usuario.lower() in ["tchau", "adeus", "sair"]: # Adicionar "sair" como opção para encerrar
print("Chatbot: Tchau! Até mais! 👋")
break
resposta_chatbot = chatbot_inteligente(mensagem_usuario) # Chamar o chatbot inteligente
print(f"Chatbot: {resposta_chatbot}")- respostas = {…}: Dicionário que mapeia cada intenção para uma lista de respostas possíveis. Você pode personalizar e expandir essas respostas!
- def chatbot_inteligente(mensagem_usuario):: Define a função chatbot_inteligente que recebe a mensagem do usuário.
- intencao_prevista = pipeline.predict([mensagem_usuario])[0]: Prever a intenção! Usa o pipeline.predict() para classificar a mensagem_usuario e obter a intencao_prevista. [mensagem_usuario] coloca a mensagem em uma lista, pois predict() espera uma lista de frases. [0] pega o primeiro (e único) elemento do array de previsões retornado por predict().
- if intencao_prevista in respostas:: Verifica se a intencao_prevista está presente como chave no dicionário respostas.
- resposta = random.choice(respostas[intencao_prevista]): Se sim, escolhe uma resposta aleatória da lista de respostas para essa intenção.
- else: resposta = random.choice(respostas[“default”]): Se não (intenção não mapeada), usa uma resposta “default” (genérica).
- return resposta: Retorna a resposta do chatbot.
- (Loop principal): Similar ao chatbot básico, mas agora chama a função chatbot_inteligente para obter a resposta. Adicionei “sair” como opção para encerrar o chatbot.
Código completo do chatbot inteligente com IA
import nltk
from nltk.stem import RSLPStemmer
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import random
# Baixar stopwords do NLTK (se não tiver baixado ainda)
nltk.download('stopwords')
# Dataset de treinamento (frases e intenções)
dataset = [
("Olá", "saudacao"),
("Oi", "saudacao"),
("E aí?", "saudacao"),
("Tudo bem?", "saudacao"),
("Como vai você?", "saudacao"),
("Qual é o seu nome?", "pergunta_nome"),
("Quem é você?", "pergunta_nome"),
("Como te chamam?", "pergunta_nome"),
("Me diga seu nome", "pergunta_nome"),
("Obrigado", "agradecimento"),
("Valeu!", "agradecimento"),
("Muito obrigado!", "agradecimento"),
("Agradeço a ajuda", "agradecimento"),
("Tchau", "despedida"),
("Adeus", "despedida"),
("Até logo", "despedida"),
("Fui!", "despedida"),
("Previsão do tempo para hoje?", "pergunta_tempo"),
("Vai chover amanhã?", "pergunta_tempo"),
("Como está o clima?", "pergunta_tempo"),
("Temperatura em São Paulo", "pergunta_tempo"),
("Conte uma piada", "conversa_aleatoria"),
("Fale sobre você", "conversa_aleatoria"),
("O que você faz?", "conversa_aleatoria"),
("Me surpreenda!", "conversa_aleatoria"),
("...", "conversa_aleatoria"), # Mensagens genéricas/não reconhecidas
("Não entendi", "conversa_aleatoria"),
("?", "conversa_aleatoria"),
("", "conversa_aleatoria"), # Mensagem vazia
]
frases, intencoes = zip(*dataset)
frases = list(frases)
intencoes = list(intencoes)
# Pipeline de Machine Learning
pipeline = Pipeline([
('tfidf', TfidfVectorizer(analyzer='word', stop_words=nltk.corpus.stopwords.words('portuguese'))),
('clf', MultinomialNB()),
])
# Dividir dados em treino e teste
frases_treino, frases_teste, intencoes_treino, intencoes_teste = train_test_split(
frases, intencoes, test_size=0.2, random_state=42
)
# Treinar o modelo
pipeline.fit(frases_treino, intencoes_treino)
# Avaliar o modelo
intencoes_preditas = pipeline.predict(frases_teste)
acuracia = accuracy_score(intencoes_teste, intencoes_preditas)
print(f"Acurácia do modelo nos dados de teste: {acuracia:.2f}")
print("\nRelatório de Classificação:")
print(classification_report(intencoes_teste, intencoes_preditas))
# Respostas predefinidas para cada intenção
respostas = {
"saudacao": ["Olá! Tudo bem por aí? 😊", "Oi! Em que posso ajudar? 😉", "Olá! Que bom te ver por aqui! 😄"],
"pergunta_nome": ["Eu sou um chatbot inteligente em Python! 🤖", "Pode me chamar de Chatbot IA! 😉", "Não tenho um nome oficial, mas sou seu chatbot amigo! 😊"],
"agradecimento": ["De nada! 😊 Sempre que precisar, pode me chamar!", "Por nada! 😉 Fico feliz em ajudar!", "Disponha! 😊"],
"despedida": ["Tchau! Foi ótimo conversar contigo! 👋", "Até mais! 😉 Volte sempre!", "Tchauzinho! 😊"],
"pergunta_tempo": ["Desculpe, ainda não consigo te dar a previsão do tempo. 😅 Mas estou aprendendo!", "Que pena, não tenho essa informação no momento. 😔", "Ainda não fui treinado para responder sobre o clima! 😅"],
"conversa_aleatoria": ["Hmm, interessante... 🤔 Conte mais!", "Não sei bem sobre isso... 😅 Mas adoro conversar!", "Que assunto curioso! 😄", "Vamos mudar de assunto? 😉"],
"default": ["Desculpe, não entendi muito bem... 🤔 Poderia reformular sua pergunta? 😉", "Não tenho certeza se compreendi... 😅 Pode tentar de novo?", "Poderia repetir, por favor? 🙏"],
}
def chatbot_inteligente(mensagem_usuario):
"""Chatbot inteligente com classificação de intenções usando Machine Learning."""
intencao_prevista = pipeline.predict([mensagem_usuario])[0]
if intencao_prevista in respostas:
resposta = random.choice(respostas[intencao_prevista])
else:
resposta = random.choice(respostas["default"])
return resposta
print("Chatbot Inteligente em Python com IA iniciado! Digite 'tchau' ou 'adeus' ou 'sair' para sair.")
while True:
mensagem_usuario = input("Você: ")
if mensagem_usuario.lower() in ["tchau", "adeus", "sair"]:
print("Chatbot: Tchau! Até mais! 👋")
break
resposta_chatbot = chatbot_inteligente(mensagem_usuario)
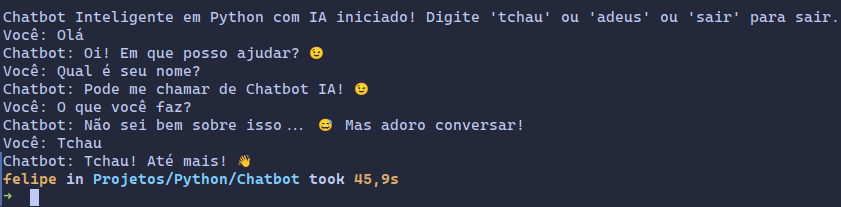
print(f"Chatbot: {resposta_chatbot}")Execute este código completo do Chatbot Inteligente com IA! Primeiro, ele irá treinar o modelo de classificação de intenções com o dataset que preparamos. Depois, você poderá conversar com o chatbot no terminal! Experimente digitar frases diferentes, mesmo variações das frases do dataset, e veja como o chatbot consegue prever a intenção e responder de forma mais inteligente do que o chatbot baseado em regras anterior.
Próximos níveis de inteligência: Expandindo o cérebro do nosso chatbot! 🚀
Por fim, com este post, você construiu um Chatbot Inteligente de verdade, com um cérebro de Machine Learning! É um grande salto em relação ao chatbot baseado em regras, e abre um mundo de possibilidades para criar robôs de conversa cada vez mais sofisticados.
Para levar nosso chatbot a um nível ainda mais alto de inteligência, podemos explorar:
- Aumentar o dataset de treinamento: Quanto mais exemplos de frases e intenções tivermos no dataset, mais robusto e preciso será o modelo de classificação. Crie um dataset maior e mais diversificado!
- Usar técnicas de PLN mais avançadas: Experimente usar word embeddings (como Word2Vec ou GloVe) ou modelos de linguagem mais complexos (como Transformers) para representar as palavras e frases de forma mais rica e semântica.
- Explorar outros algoritmos de classificação: Teste diferentes algoritmos de Machine Learning para classificação de texto, como Support Vector Machines (SVM), Random Forests, Redes Neurais, e compare os resultados.
- Adicionar reconhecimento de entidades nomeadas (NER): Incorpore técnicas de NER para identificar entidades relevantes nas mensagens dos usuários (nomes, datas, lugares, etc.) e usar essas informações para gerar respostas ainda mais personalizadas e contextuais.
- Criar chatbots contextuais e com memória: Desenvolva chatbots que consigam manter o contexto da conversa, lembrar de informações trocadas anteriormente e ter diálogos mais longos e complexos.
Lembre-se, a Inteligência Artificial Conversacional é um campo em constante evolução, e a jornada para criar chatbots verdadeiramente inteligentes é longa e desafiadora, mas incrivelmente recompensadora! Então, continue praticando, experimentando, aprofundando seus conhecimentos e você se tornará um mestre em dar “cérebros de IA” para seus robôs de conversa!
E aí, o que achou de dar um cérebro de Machine Learning para o seu chatbot? Experimente rodar o código, personalize o dataset, as respostas, explore outras técnicas de PLN e Machine Learning e veja o quão longe você consegue levar a inteligência do seu robô de conversa! E não se esqueça de compartilhar suas dúvidas, ideias e criações nos comentários! Adoramos aprender e evoluir juntos! 😊
Até a próxima, e continue construindo o futuro da IA Conversacional em Python! 🚀✨💬🧠🤖