

No nosso último encontro, demos os primeiros passos na Inteligência Artificial com a Regressão Linear. Aprendemos a prever valores numéricos, lembra? Contudo, nem sempre queremos prever números. Muitas vezes, o que precisamos é organizar e categorizar informações de forma esperta, e é aí que entra a Classificação Inteligente com Python! Neste post, vamos mergulhar no mundo da classificação, entender o que é, como funciona e, principalmente, como usar Python e Machine Learning para criar sistemas que separam o “joio do trigo” com inteligência e precisão. Prepare-se para aprender a classificar dados como um mestre! 🧙♂️
Neste post, vamos mergulhar no mundo da classificação, entender o que é, como funciona e, principalmente, como usar Python e Machine Learning para criar sistemas que separam o “joio do trigo” com inteligência e precisão. Prepare-se para aprender a classificar dados como um mestre! 🧙♂️
O poder da classificação: Organizando o mundo em categorias 🗂️
Primeiramente, vamos entender a essência da Classificação Inteligente. Imagine a seguinte situação: você recebe um monte de e-mails e precisa separá-los entre “spam” e “não spam”. Ou então, você tem diversas fotos de frutas e precisa identificar quais são maçãs, bananas, laranjas, etc. Essas são tarefas de classificação!
Em essência, a classificação no Machine Learning consiste em atribuir uma categoria ou rótulo a um determinado dado de entrada. Ou seja, diferente da Regressão Linear, que prevê valores contínuos (como o preço de uma casa), a classificação prevê categorias discretas (como “spam” ou “não spam”, “maçã” ou “banana”).
Para ilustrar melhor, pense em alguns exemplos práticos de classificação que usamos no dia a dia:
- Detecção de Spam: Seu provedor de e-mail usa algoritmos de classificação para identificar quais e-mails são spam e quais são legítimos, protegendo sua caixa de entrada.
- Reconhecimento de Imagens: Aplicativos de fotos usam classificação para identificar objetos em imagens, como pessoas, animais, carros, paisagens, etc.
- Diagnóstico Médico: Sistemas de IA podem auxiliar médicos na classificação de exames, como radiografias e tomografias, para identificar doenças ou anomalias.
- Análise de Sentimentos: Redes sociais e plataformas de avaliação usam classificação para determinar se um texto expressa um sentimento positivo, negativo ou neutro.
Algoritmos de classificação: As ferramentas do classificador inteligente 🛠️
Assim como na Regressão Linear, existem diversos algoritmos de Machine Learning que podemos usar para realizar tarefas de classificação. Alguns dos mais populares são:
- Regressão Logística: Apesar do nome “Regressão”, é um algoritmo de classificação muito utilizado, especialmente para problemas de classificação binária (com duas classes).
- Árvores de Decisão: Algoritmos que criam uma estrutura em forma de árvore para tomar decisões de classificação, seguindo uma série de perguntas e respostas.
- Support Vector Machines (SVM): Algoritmos poderosos que buscam encontrar a “melhor fronteira” para separar diferentes classes de dados.
- K-Nearest Neighbors (KNN): Algoritmos simples que classificam um novo dado com base na categoria dos seus vizinhos mais próximos.
- Redes Neurais: Modelos mais complexos e flexíveis que podem ser usados para resolver problemas de classificação mais desafiadores, especialmente com grandes volumes de dados.
Mão na massa: Classificação de flores íris com Python e Scikit-Learn 🌸
Agora, vamos para a parte prática! Vamos usar o famoso dataset “Iris” para criar um modelo de classificação em Python com scikit-learn. O dataset Iris contém medidas de diferentes partes de flores de três espécies diferentes (Setosa, Versicolor e Virginica). Nosso objetivo será construir um classificador que, dadas as medidas de uma flor, consiga dizer a qual espécie ela pertence.
Instalação das dependências
Primeiro passo, como sempre, é instalar as bibliotecas necessárias:
pip install numpy matplotlib scikit-learn seaborn
Importação das dependências
Agora, crie um arquivo python no editor de sua preferência, e importe as bibliotecas necessárias:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import seaborn as sns # Biblioteca para visualização da matriz de confusão- sklearn.datasets.load_iris: Função do scikit-learn para carregar o dataset Iris.
- sklearn.model_selection.train_test_split: Função para dividir os dados em conjuntos de treino e teste.
- sklearn.linear_model.LogisticRegression: Classe do scikit-learn que implementa o algoritmo de Regressão Logística.
- sklearn.metrics.accuracy_score, sklearn.metrics.confusion_matrix, sklearn.metrics.classification_report: Funções para avaliar o desempenho do modelo de classificação.
- seaborn (sns): Biblioteca para visualização de dados, usaremos para plotar a matriz de confusão de forma mais elegante.
Carregar o dataset iris
Em seguida, vamos carregar o dataset Iris e explorar um pouco os dados:
# Carregar o dataset Iris
iris = load_iris()
X = iris.data # Características (features) das flores
y = iris.target # Espécies das flores (rótulos)
nomes_classes = iris.target_names # Nomes das classes
print("Nomes das classes:", nomes_classes)
print("Formato dos dados (X):", X.shape)
print("Formato dos rótulos (y):", y.shape)- iris = load_iris(): Carrega o dataset Iris.
- X = iris.data: Atribui as características das flores (medidas) à variável X.
- y = iris.target: Atribui os rótulos das espécies (0, 1, 2) à variável y.
- nomes_classes = iris.target_names: Atribui os nomes das classes (setosa, versicolor, virginica).
- print(…): Imprime os nomes das classes e os formatos dos dados e rótulos para termos uma ideia do que estamos trabalhando.
Preparar os dados de treino
Agora, vamos dividir os dados em conjuntos de treino e teste. É fundamental fazer isso para avaliar o desempenho do nosso modelo em dados que ele nunca viu antes.
# Dividir os dados em treino e teste
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size=0.3, random_state=42) # 30% para teste
train_test_split(…): Divide os dados em 70% para treino e 30% para teste. test_size=0.3 define a proporção para teste. random_state=42 garante que a divisão seja a mesma sempre que rodarmos o código (para reprodutibilidade).
Treinamento do modelo
Com os dados preparados, vamos criar e treinar nosso modelo de Regressão Logística:
# Criar o modelo de Regressão Logística
modelo = LogisticRegression(max_iter=1000) # Aumentar max_iter para garantir convergência
# Treinar o modelo com os dados de treino
modelo.fit(X_treino, y_treino)- modelo = LogisticRegression(max_iter=1000): Cria uma instância do modelo de Regressão Logística.
max_iter=1000aumenta o número máximo de iterações para garantir que o algoritmo encontre uma solução. - modelo.fit(X_treino, y_treino): Treina o modelo usando os dados de treino (X_treino e y_treino).
Realizando previsões com o modelo
Modelo treinado, hora de fazer previsões nos dados de teste e avaliar o desempenho:
# Fazer previsões nos dados de teste
y_predito = modelo.predict(X_teste)
# Avaliar o modelo
acuracia = accuracy_score(y_teste, y_predito)
matriz_confusao = confusion_matrix(y_teste, y_predito)
relatorio_classificacao = classification_report(y_teste, y_predito, target_names=nomes_classes)
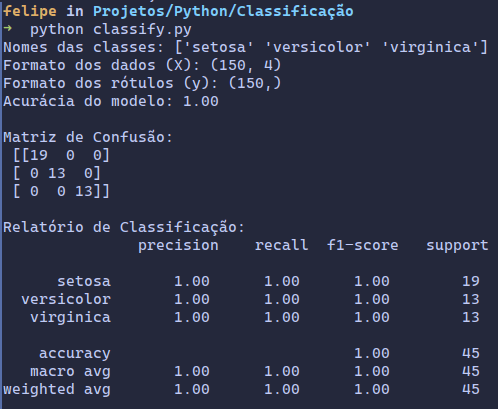
print(f"Acurácia do modelo: {acuracia:.2f}")
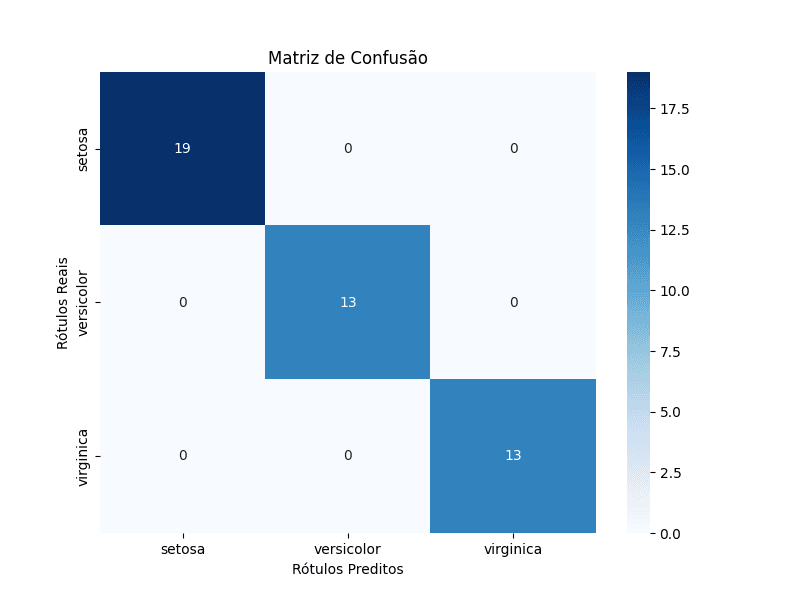
print("\nMatriz de Confusão:\n", matriz_confusao)
plt.figure(figsize=(8, 6)) # Ajustar tamanho da figura para melhor visualização
sns.heatmap(matriz_confusao, annot=True, fmt="d", cmap="Blues",
xticklabels=nomes_classes, yticklabels=nomes_classes) # Heatmap da matriz de confusão
plt.xlabel('Rótulos Preditos')
plt.ylabel('Rótulos Reais')
plt.title('Matriz de Confusão')
plt.show()
print("\nRelatório de Classificação:\n", relatorio_classificacao)- y_predito = modelo.predict(X_teste): Faz previsões usando o modelo nos dados de teste (X_teste).
- acuracia = accuracy_score(…): Calcula a acurácia, que é a proporção de classificações corretas.
- matriz_confusao = confusion_matrix(…): Calcula a matriz de confusão, que mostra o número de verdadeiros positivos, verdadeiros negativos, falsos positivos e falsos negativos para cada classe.
- relatorio_classificacao = classification_report(…): Gera um relatório de classificação mais detalhado, com precisão, recall, f1-score e suporte para cada classe.
- print(…): Imprime a acurácia, a matriz de confusão (em formato de texto e heatmap visual) e o relatório de classificação.
- sns.heatmap(…): Cria um heatmap (mapa de calor) da matriz de confusão usando a biblioteca seaborn para uma visualização mais intuitiva.
Código Completo:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import seaborn as sns
# Carregar o dataset Iris
iris = load_iris()
X = iris.data
y = iris.target
nomes_classes = iris.target_names
print("Nomes das classes:", nomes_classes)
print("Formato dos dados (X):", X.shape)
print("Formato dos rótulos (y):", y.shape)
# Dividir os dados em treino e teste
X_treino, X_teste, y_treino, y_teste = train_test_split(X, y, test_size=0.3, random_state=42)
# Criar o modelo de Regressão Logística
modelo = LogisticRegression(max_iter=1000)
# Treinar o modelo com os dados de treino
modelo.fit(X_treino, y_treino)
# Fazer previsões nos dados de teste
y_predito = modelo.predict(X_teste)
# Avaliar o modelo
acuracia = accuracy_score(y_teste, y_predito)
matriz_confusao = confusion_matrix(y_teste, y_predito)
relatorio_classificacao = classification_report(y_teste, y_predito, target_names=nomes_classes)
print(f"Acurácia do modelo: {acuracia:.2f}")
print("\nMatriz de Confusão:\n", matriz_confusao)
plt.figure(figsize=(8, 6))
sns.heatmap(matriz_confusao, annot=True, fmt="d", cmap="Blues",
xticklabels=nomes_classes, yticklabels=nomes_classes)
plt.xlabel('Rótulos Preditos')
plt.ylabel('Rótulos Reais')
plt.title('Matriz de Confusão')
plt.show()
print("\nRelatório de Classificação:\n", relatorio_classificacao)Execute este código e você verá a acurácia do modelo, a matriz de confusão visualizada como um heatmap e o relatório de classificação completo. Com efeito, você terá criado e avaliado seu primeiro modelo de Classificação Inteligente!
Parabéns! Você Separou o Joio do Trigo com IA! 🌾🎉
Em resumo, neste post, você aprendeu o conceito de Classificação Inteligente, explorou alguns algoritmos populares e, mais importante, construiu um classificador funcional em Python usando o dataset Iris. Agora, você tem as ferramentas para começar a criar seus próprios sistemas de classificação para diversas aplicações!
Lembre-se, a classificação é uma das tarefas mais importantes e versáteis no Machine Learning e na IA. Portanto, dominar esses conceitos e técnicas abre um leque enorme de possibilidades para você explorar e criar soluções inteligentes.
E então, preparado para classificar tudo? Experimente rodar o código, mude o algoritmo de classificação (tente uma Árvore de Decisão, por exemplo!), explore outros datasets de classificação e veja os resultados. E não se esqueça, se tiver qualquer dúvida ou quiser compartilhar suas descobertas, deixe um comentário aqui embaixo! A troca de ideias é sempre muito valiosa! 😊
Até a próxima, e continue trilhando o caminho da Inteligência Artificial com Python! 🚀✨
3 comentários em “Classificação inteligente: Separando o joio do trigo com Python e Machine Learning”